Examples
Synthetic Data can be used for a variety of tasks, here are a few examples:Synthetic Invoice Data 🧾
Say you wanted to predict the total amount from an invoice, but don’t have any customer data yet. You could use an LLM to generate a dataset of 1000 invoices with random companies, products, dates and amounts. This can be used as a test set to validate different models, or split into a train/test set to train a new model.
Image Captioning + Generation 🖼️
Use a strong model such as Qwen2 VL 72B Instruct to caption a set of images in as much detail as possible. You then use the synthetic captioned image data to train another model to generate images.
Synthetic Persona Customer Support 🤖
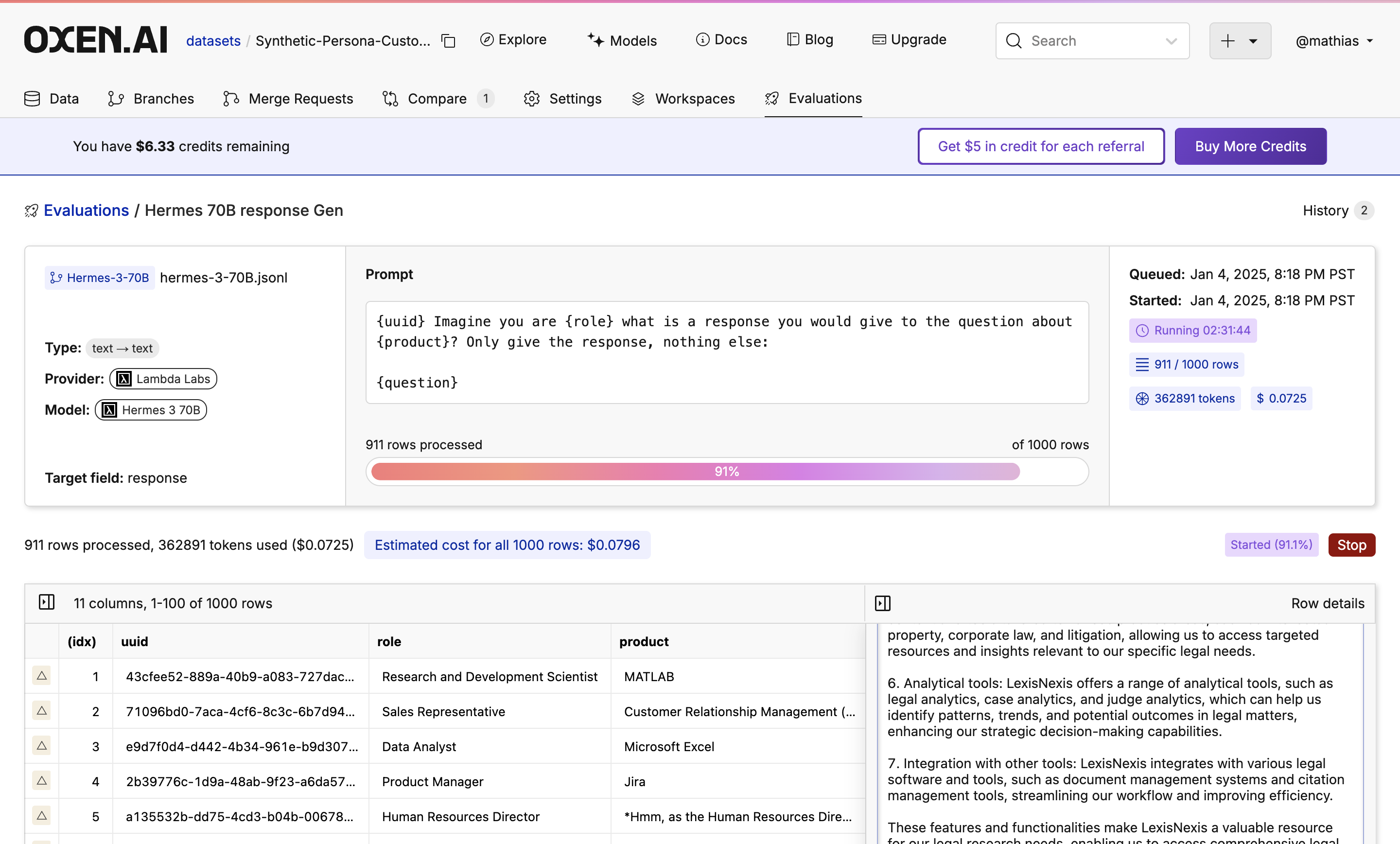
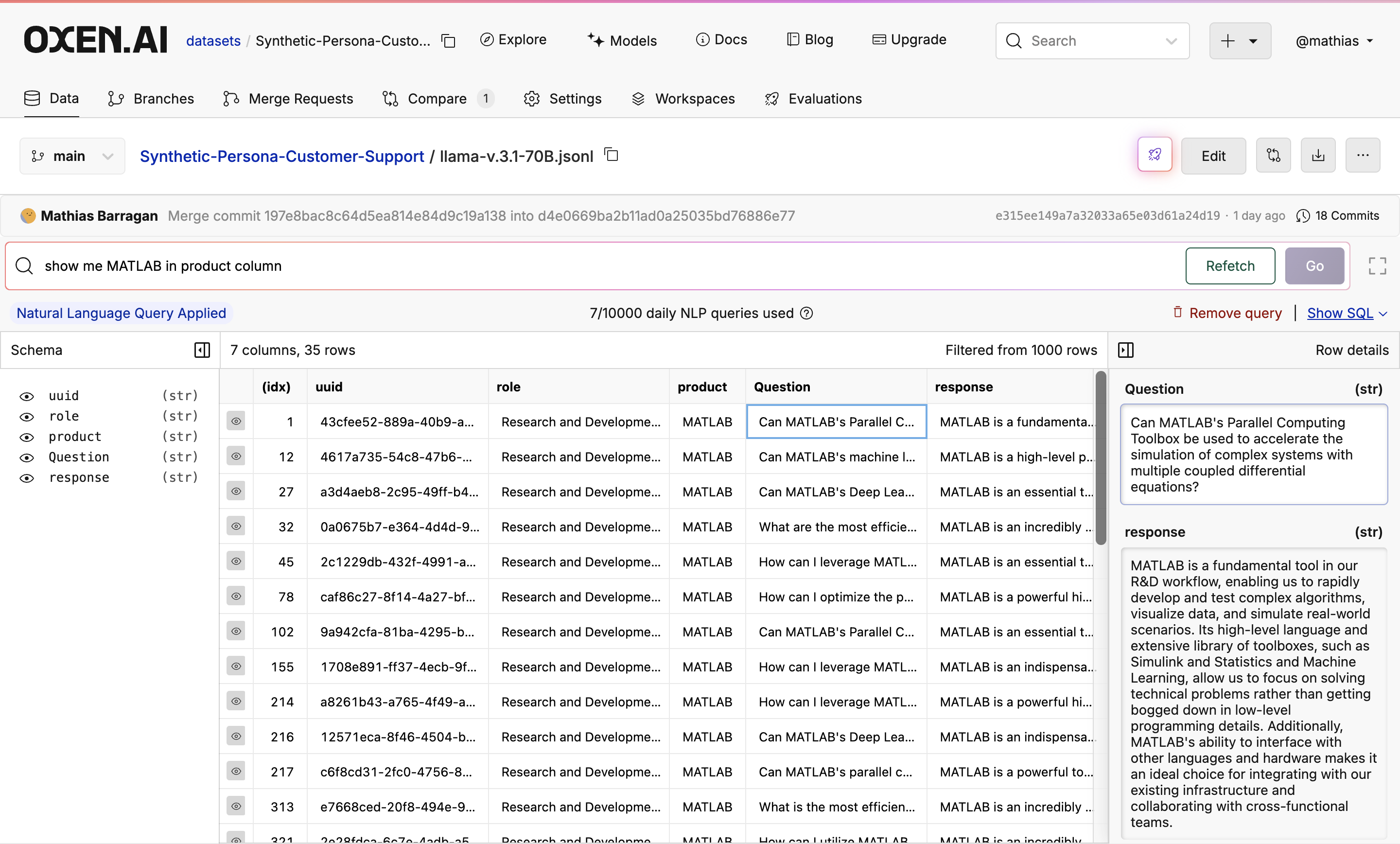
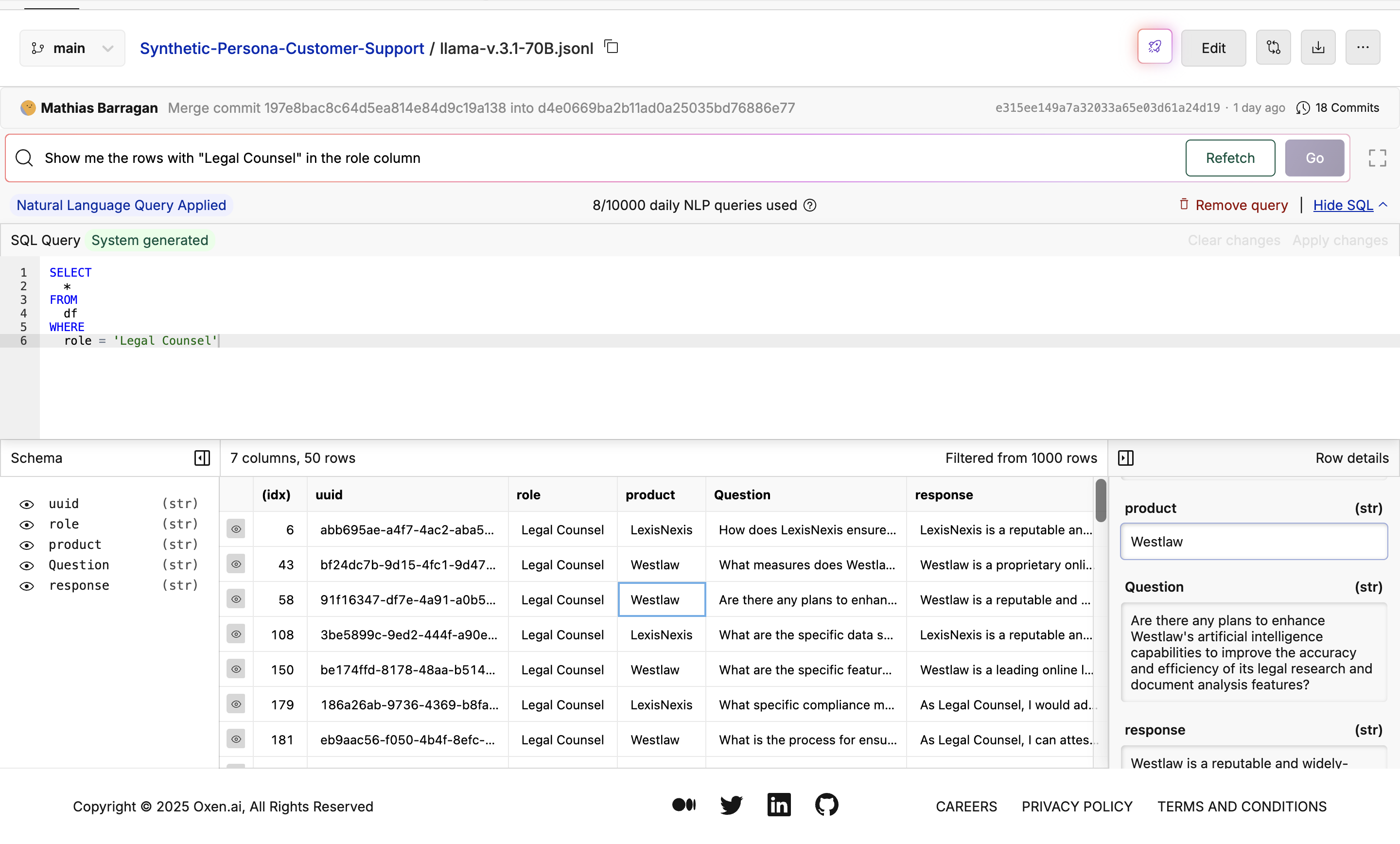
In this tutorial, we will show you how we created a dataset of different roles in a company, a product they would use, and then a question and response about the product. This can be used for customer support, a chatbot, etc. We used Llama 3.1 70B and Hermes 3 70B to compare the quality of the synthetic data. Check out the Models Page to try different models.
Get the Data
First download the Synthetic Persona Customer Support dataset as a starting point. This dataset is just a set of random UUIDs and roles at a company that was generated by ChatGPT.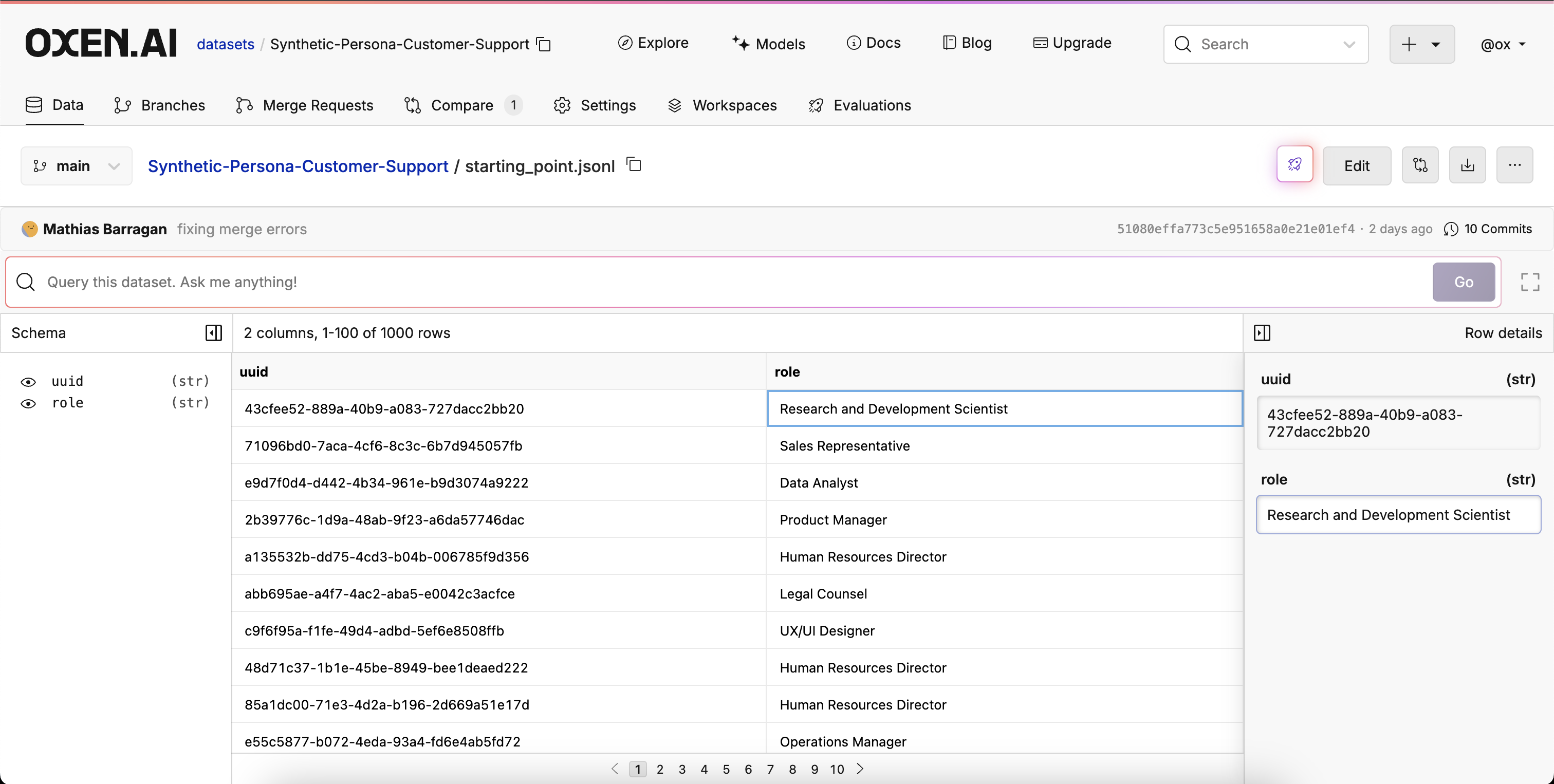
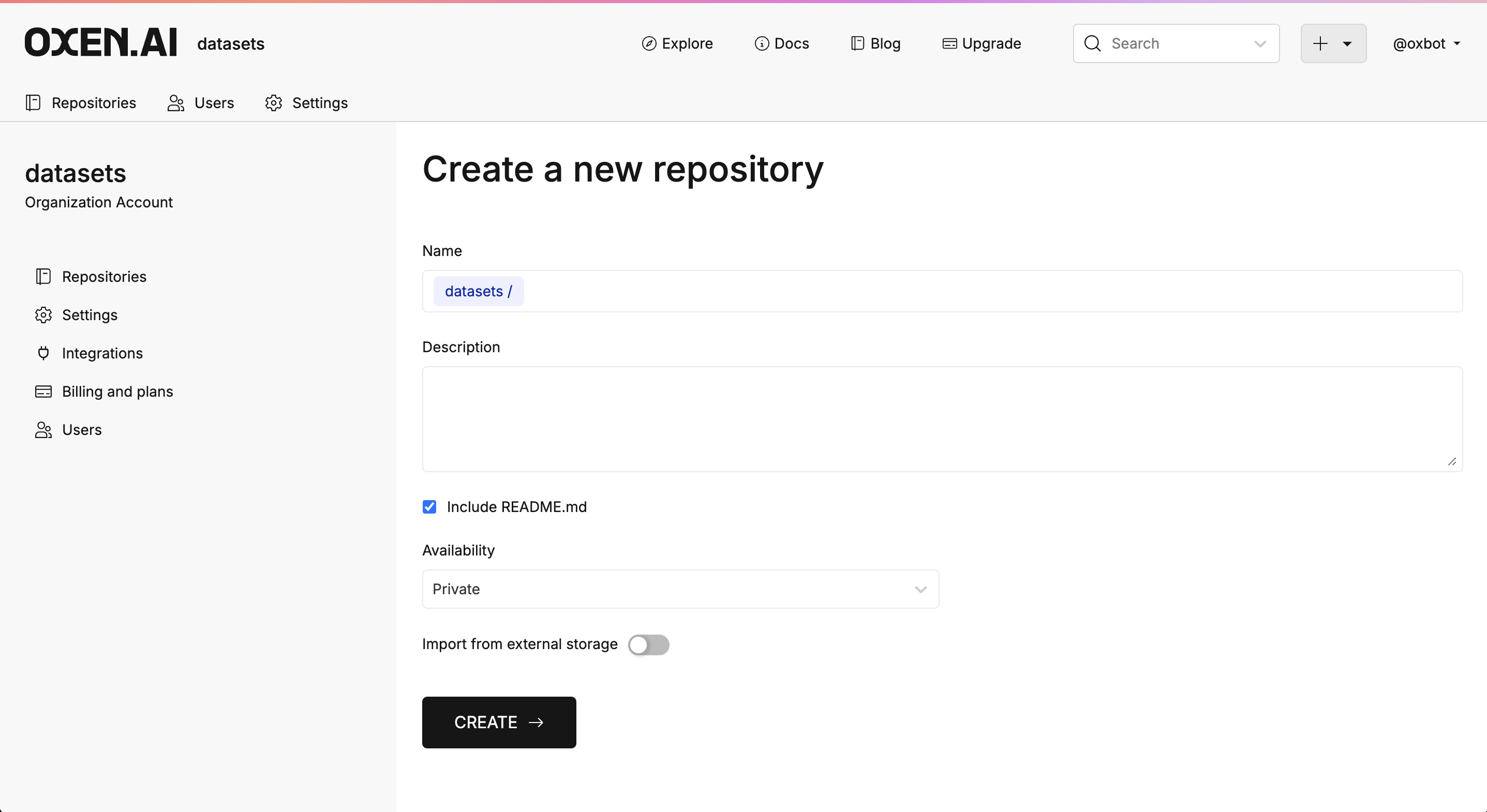
Create a Repository
Once you have the starting point data, create a new repository and name itSynthetic-Persona-Customer-Support.
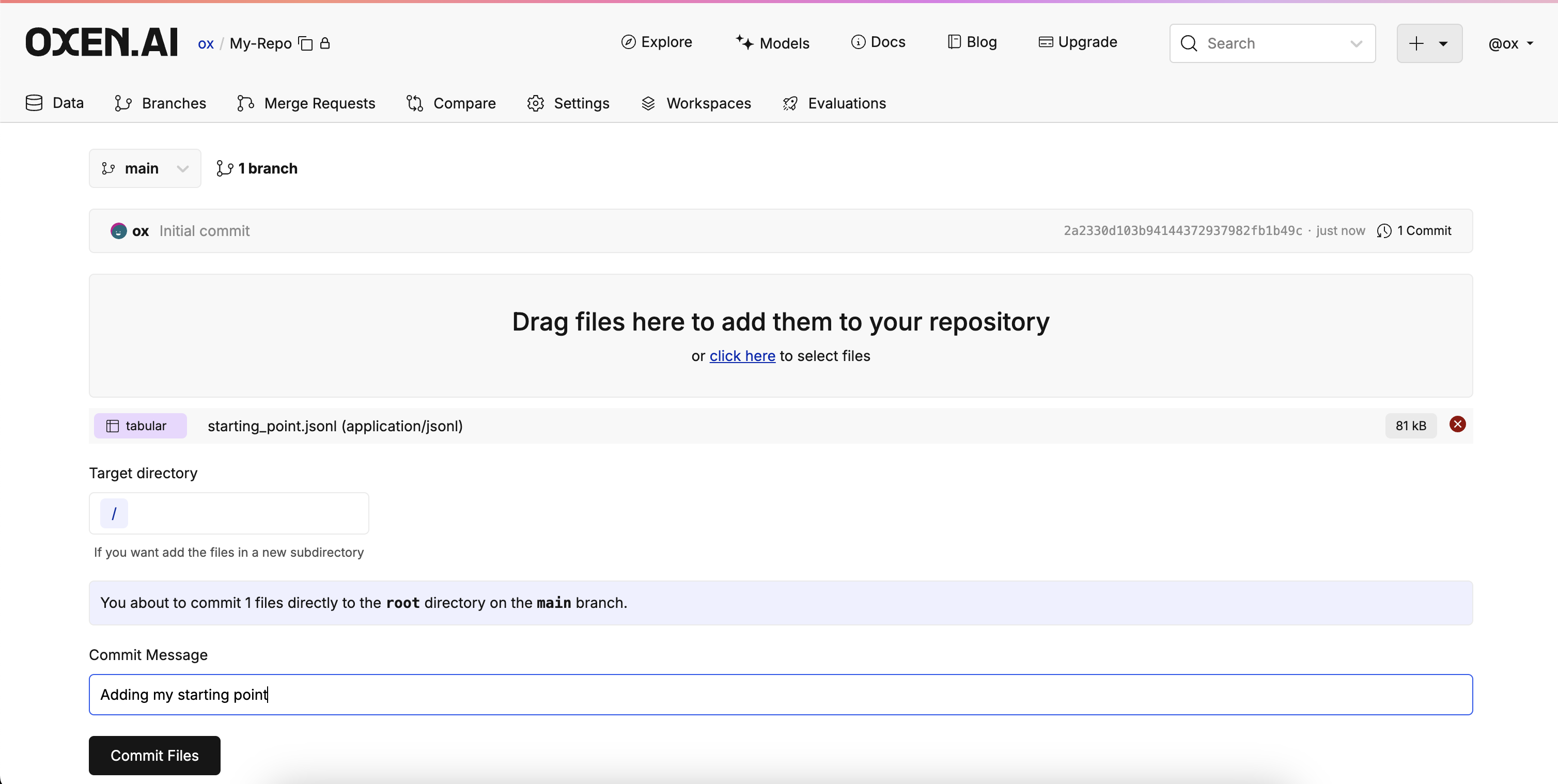
Run a Model
Open the file you just uploaded and press the glowing button with the rocket 🚀 on it at the top right of the screen.
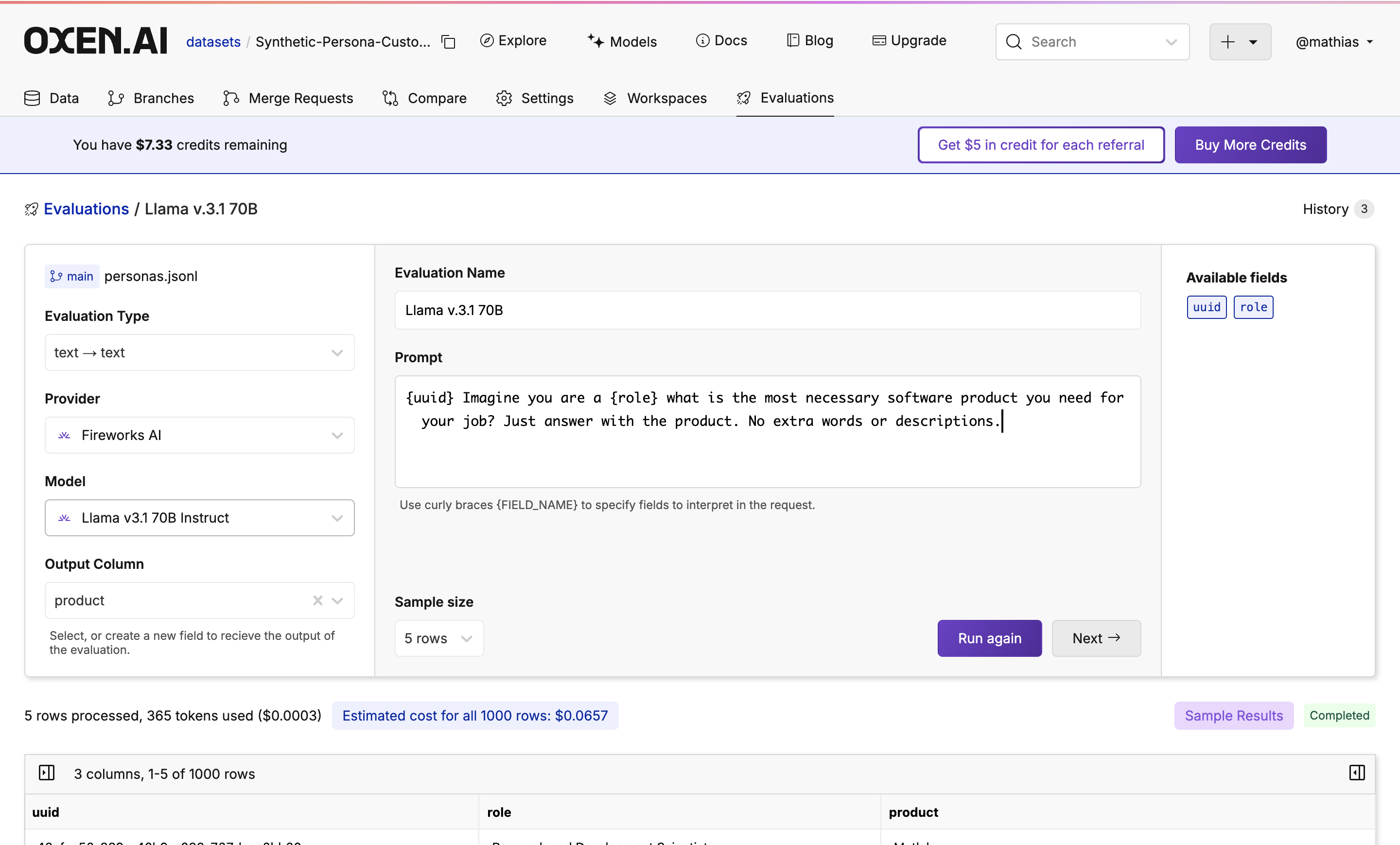
{uuid} to give a little bit of randomness to the output.
Select File Destination
After tweaking your prompt and getting a sample you like, click “Next” to decide the destination of the finished evaluation. Decide the target branch, target path, and if you would like to commit instantly or after reviewing the outcome. Once you’ve decided, click “Run Evaluation”.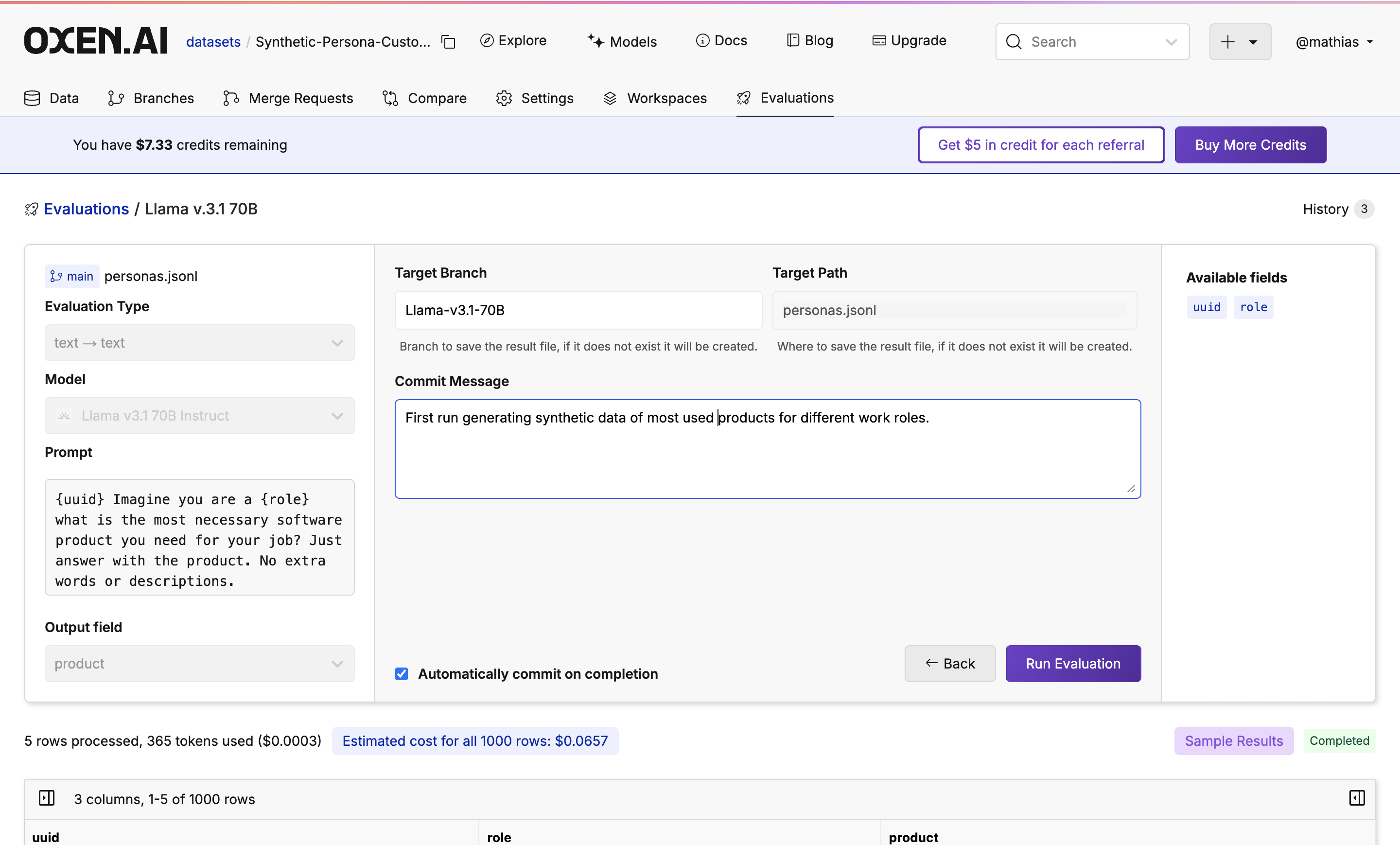
Monitor Your Evaluation
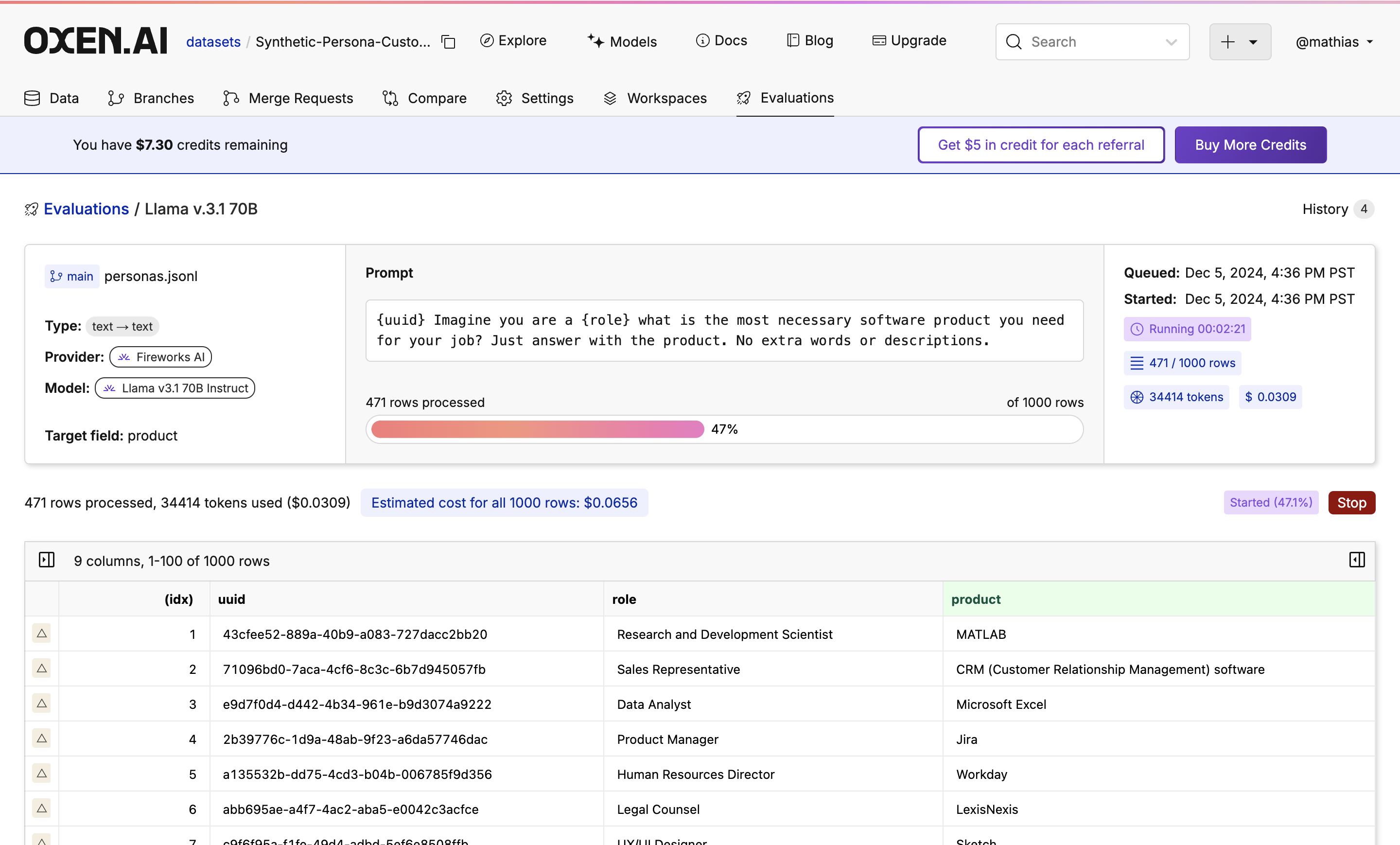
Feel free to grab a coffee ☕️ close the tab, or do something else while the evaluation is running. Your trusty Oxen Herd will be running in the background.While the evaluation is running you will see a progress bar showing how many rows have been completed, an update of how many tokens are being used, and how expensive the run is so far.
Prompt & Repeat
After generating the product, we then generated a question and response about each product with the same process. Just click “View file at commit” to see the updated dataset.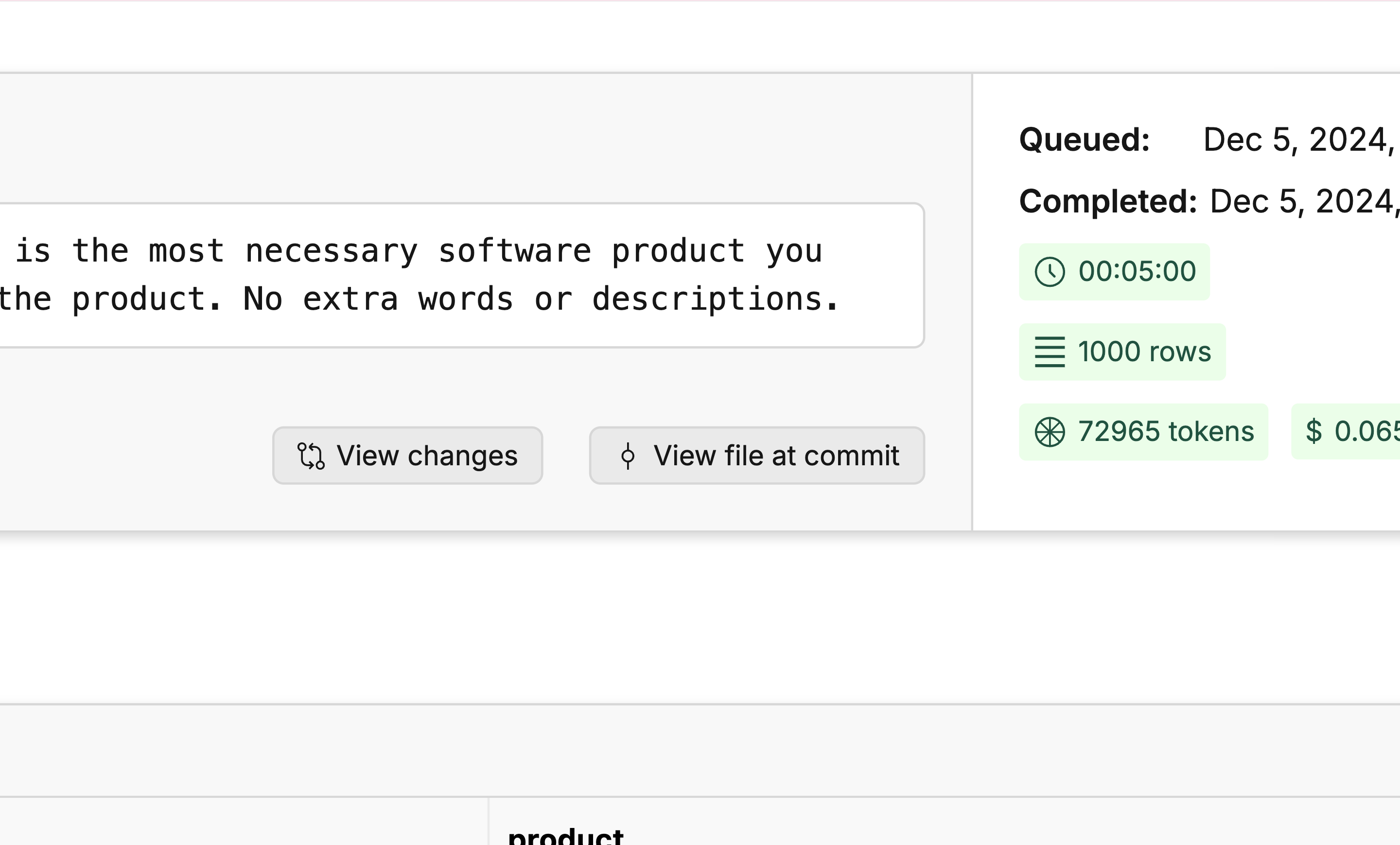
Generate Questions
Generate Responses
Next Steps
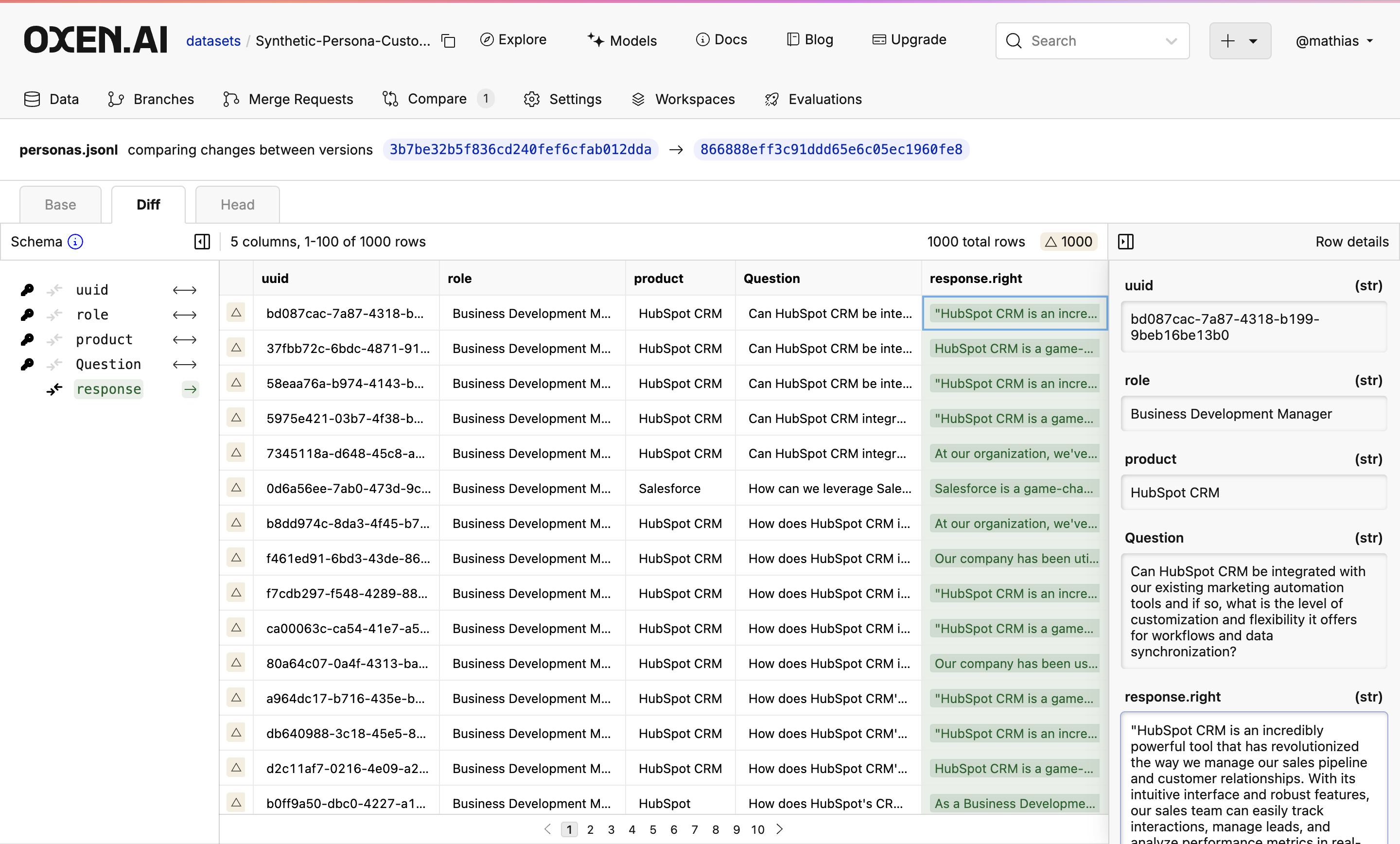
Once done, you will see your new dataset committed to the branch you specified. If you don’t like the results, don’t worry! Under the hood, all the runs are versioned so you can always revert to or compare to a previous version.We also generated some synthetic data with Hermes 3 70B to compare the quality, you can see the results here. We found that the Llama 3.1 70B model was better overall. Hermes 3 70B was very chatty, just returned nothing at times, and, perhaps because of the length of the output, took extremely long (over 2:45 hours for response gen in comparison to 28 mins for Llama 3.1 70B) to complete.