Documentation Index
Fetch the complete documentation index at: https://docs.oxen.ai/llms.txt
Use this file to discover all available pages before exploring further.
 Oxen.ai gives you the tools to fine-tune open source models on your own datasets. We believe that your data is your differentiator, and training models on your own data should be easy, fast, and approachable for everyone.
The platform makes it easy to spin up GPU infrastructure to train models or run inference at scale. Never lose track of which dataset trained which model because all files are version controlled in a repository. Kick off many experiments in parallel and easily collaborate with your team.
Oxen.ai gives you the tools to fine-tune open source models on your own datasets. We believe that your data is your differentiator, and training models on your own data should be easy, fast, and approachable for everyone.
The platform makes it easy to spin up GPU infrastructure to train models or run inference at scale. Never lose track of which dataset trained which model because all files are version controlled in a repository. Kick off many experiments in parallel and easily collaborate with your team.
✅ Features
Oxen.ai allows you to own your model end to end, from curating datasets to fine-tuning models to deploying them at scale. Start by trying out the latest and greatest open source LLM, video generation, or image editing models, then graduate to fine-tuning your own models.
- ⚙️ Fine-Tuning - Train models for many modalities (text, images, videos)
- 📊 Datasets - Build datasets for training, fine-tuning, or evaluating models
- ⚡️ Inference APIs - Deploy fine-tuned models to an API endpoint
- 🚀 Batch Inference - Run your model at scale over large datasets, to label data, generate synthetic data or evaluate model performance
⚙️ Fine-Tune Models
The best models are the ones that understand your context and continue to learn from your data over time.
Go from dataset to model in a few clicks with Oxen.ai’s fine-tuning tooling. Select a dataset, define your inputs and outputs, and let Oxen.ai do the grunt work. Oxen saves model weights to it’s version store tying model weights to the dataset and code that was used to train them.
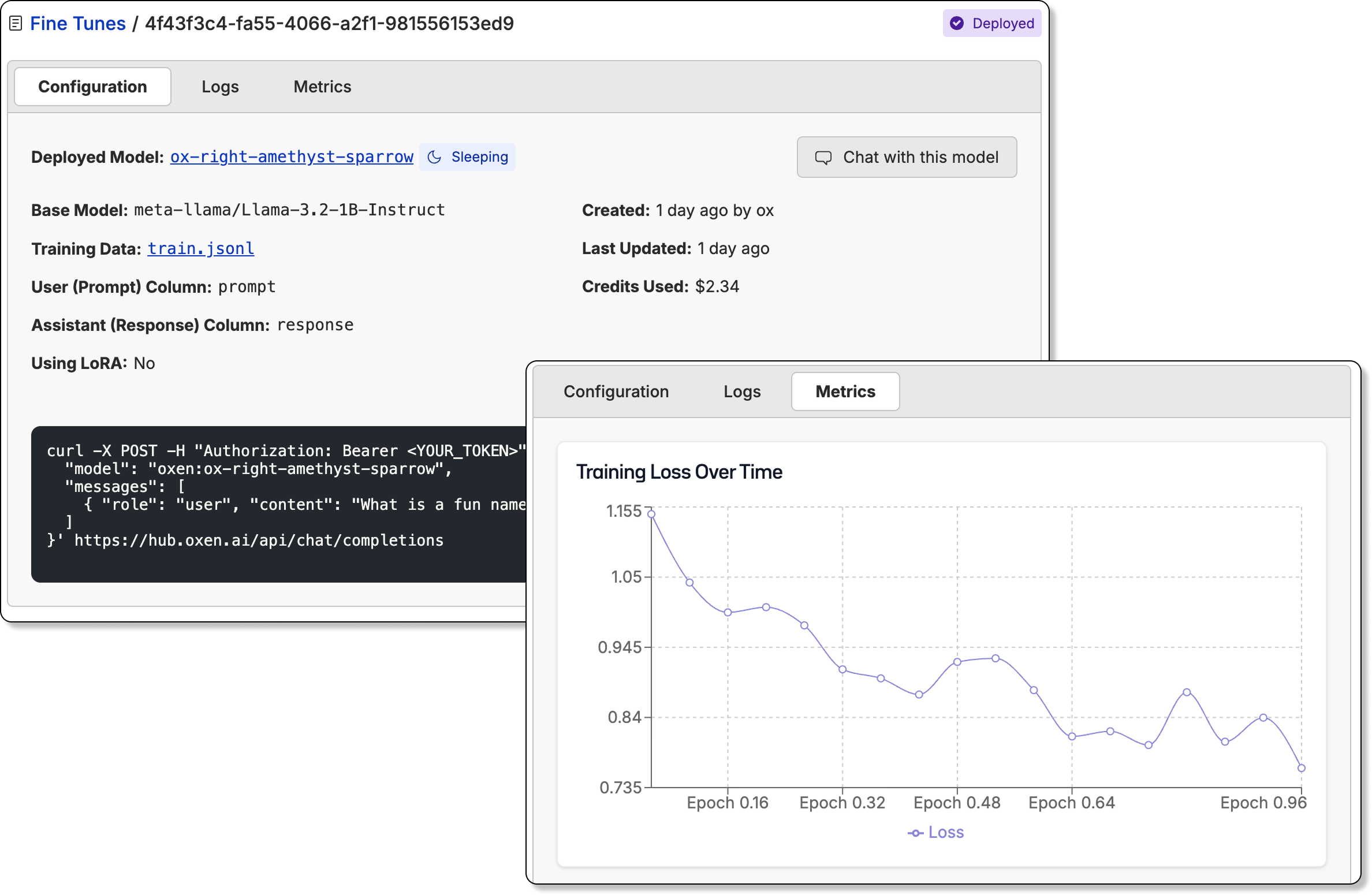 Once the model has been fine-tuned, you can easily deploy the model behind an inference endpoint and start the evaluation loop over again.
Once the model has been fine-tuned, you can easily deploy the model behind an inference endpoint and start the evaluation loop over again.
📊 Build Datasets
Quality datasets are what bring your unique style and differentiation to the model. Collaborate on multi-modal datasets used for training, fine-tuning, or evaluating models. Backed by Oxen.ai’s version control, you’ll never worry about remembering what data a model was trained or evaluated on.
Learn how to interface with datasets in the Oxen.ai python library or more about supported dataset types and formats here.
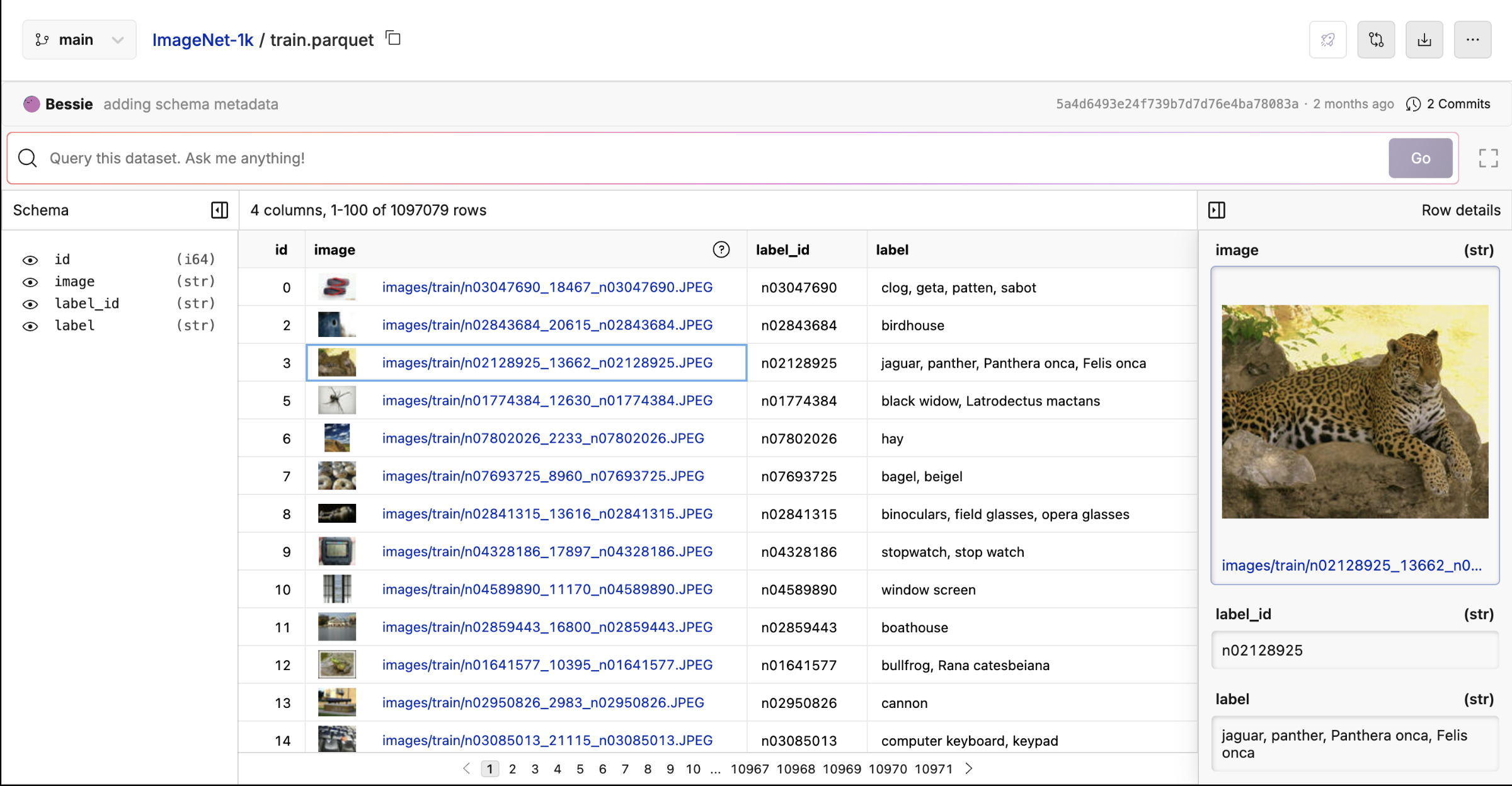
⚡ Model Inference
Whether you are making your first LLM call or need to deploy a fine-tuned model, Oxen.ai gives you the flexibility to swap models through a unified model inference API. The API is OpenAI compatible and supports a variety of foundation models as well as fine-tunable models. See the list of supported models to get started.
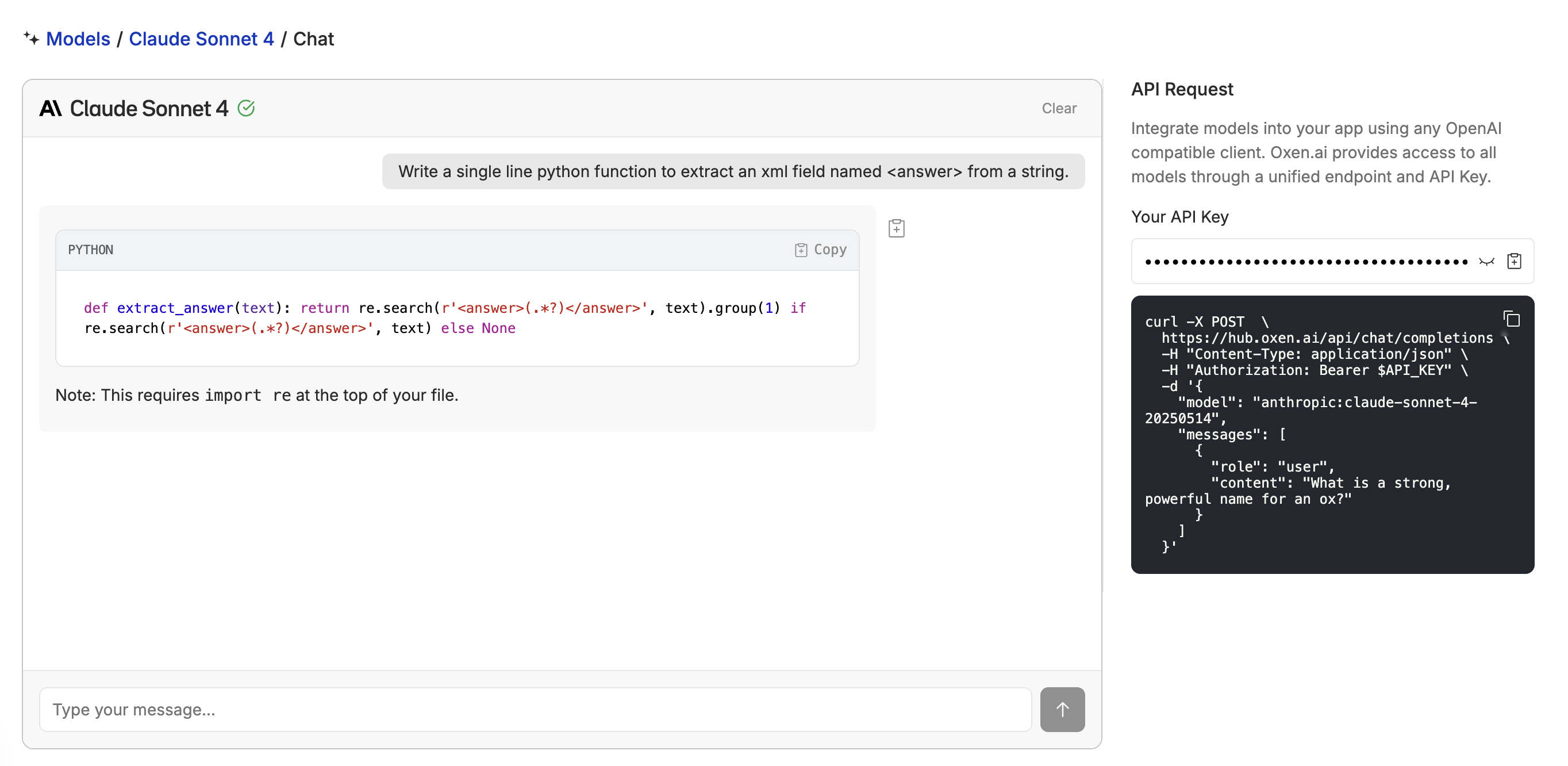 The while calling inference API is a great place to start, the real power of Oxen.ai is being able to take an open source model and fine-tune it on your own data, optimizing it for accuracy, speed, or quality. Once it’s fine-tuned, you can deploy it to the same interface in minutes. No DevOps or MLOps experience required.
The while calling inference API is a great place to start, the real power of Oxen.ai is being able to take an open source model and fine-tune it on your own data, optimizing it for accuracy, speed, or quality. Once it’s fine-tuned, you can deploy it to the same interface in minutes. No DevOps or MLOps experience required.
🚀 Run Models at Scale
Find the best model and prompt for your use case. Leverage your own datasets to build custom evaluations. Evaluation results are versioned and saved as datasets in the repository for easy performance tracking over time.
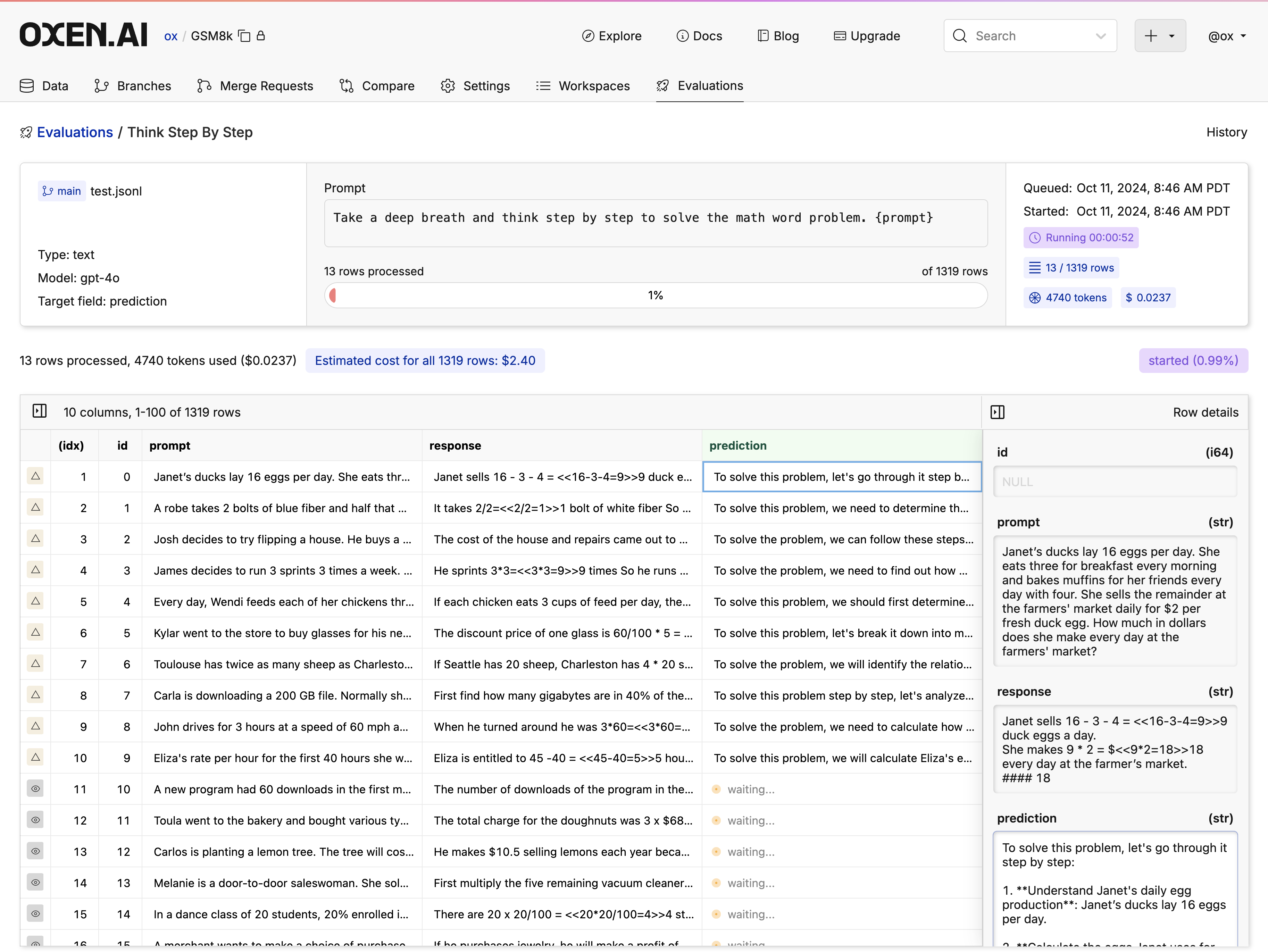
💾 Version Control
The through line of Oxen.ai is that all model weights, datasets, and code are versioned and can be stored in a single repository. This makes it easy to track changes, compare models, and share datasets with your team. You can interact with the repository through the command line interface, python library, or web interface.
We built the version control system to be blazing fast, open source, and extensible for anyone to build upon. It can be used to version any type of data, not just machine learning datasets. It scales up to monorepos with millions of files and terabytes of data.
🔒 Own Your AI
At Oxen.ai, we believe you should own your AI, don’t rent it. Owning your AI means that you can easily differentiate and extend a model’s capabilities. You are not reliant on what the model was originally trained on. This means you can create models that are smarter in your domain, higher quality, more consistent, and better than the competition.
For image or video generation, you may differentiate by bringing your own unique style to a model and make sure the generations are consistent. For language models, optimize for speed, cost, privacy, or custom domain knowledge. What ever type of model you are using, you should have the flexibility to train and deploy the model anywhere.
🌾 Why Build Oxen?
Oxen was built by a team of machine learning engineers, who have spent countless hours in their careers managing datasets and training models. We have used many different tools, but none of them were as easy to use and as ergonomic as we would like.
Production grade AI applications are constantly juggling models, datasets, and code, and it’s easy to get lost. Let alone the late nights installing the proper cuda and pytorch versions. If you have every been stuck dumping massive model weights and datasets to S3 in tarballs with little visibility, we feel your pain.
Oxen is the tool we wish we had to abstract away the infrastructure and focus on the fun parts of building AI applications.
🐂 Why the name Oxen?
“Oxen” comes from the fact that we take care of the grunt work of the infrastructure for you. Oxen love will plow, maintain, and version your data and models like a good farmer tends to their fields 🌾. During the agricultural revolution, the oxen pulling plows offloaded work and helped people specialize and start working on other important societal tasks. Let Oxen take care of the heavy infrastructure work so you can focus on solving the higher-level problems that matter to your product.