If you’re a student and want to reference a textbook for any questions you have to your AI, you would use RAG to ensure it answers based on the textbook. If a business wants to know “What was the total amount of the invoice?” the LLM would access the invoice, comb through it to get the total amount, and answer with the correct number.Evaluating how well your model can extract answers is an important part of building a robust pipeline. You may want to tweak your prompt, evaluate different models, and continuously add new data to your dataset to improve the quality of your results.
Upload Your Dataset
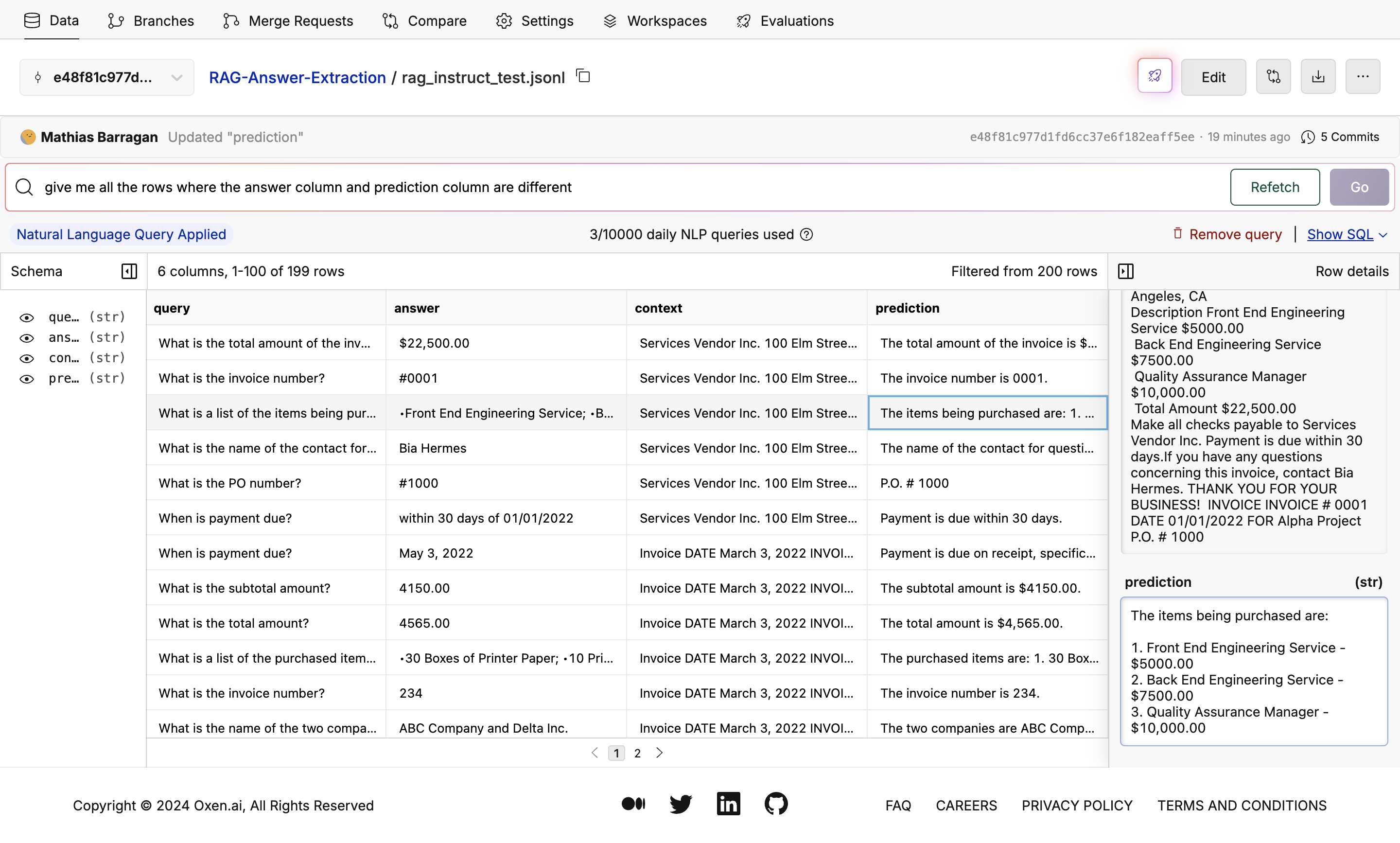
Open the dataset you want to work with. You can find an example dataset on our explore page or if you want to follow along with the example, you can clone the RAG Answer Extraction dataset we are using. We’re going to use a subset of the 50,000 rows available (that would take foreverrr) so if you want to do the same go to the branch ‘train_data_subset’.
Create a Model Evaluation
Open the file you want to use and press the glowing button with the rocket 🚀 on it at the top right of the screen.
Setting Up The Evaluation
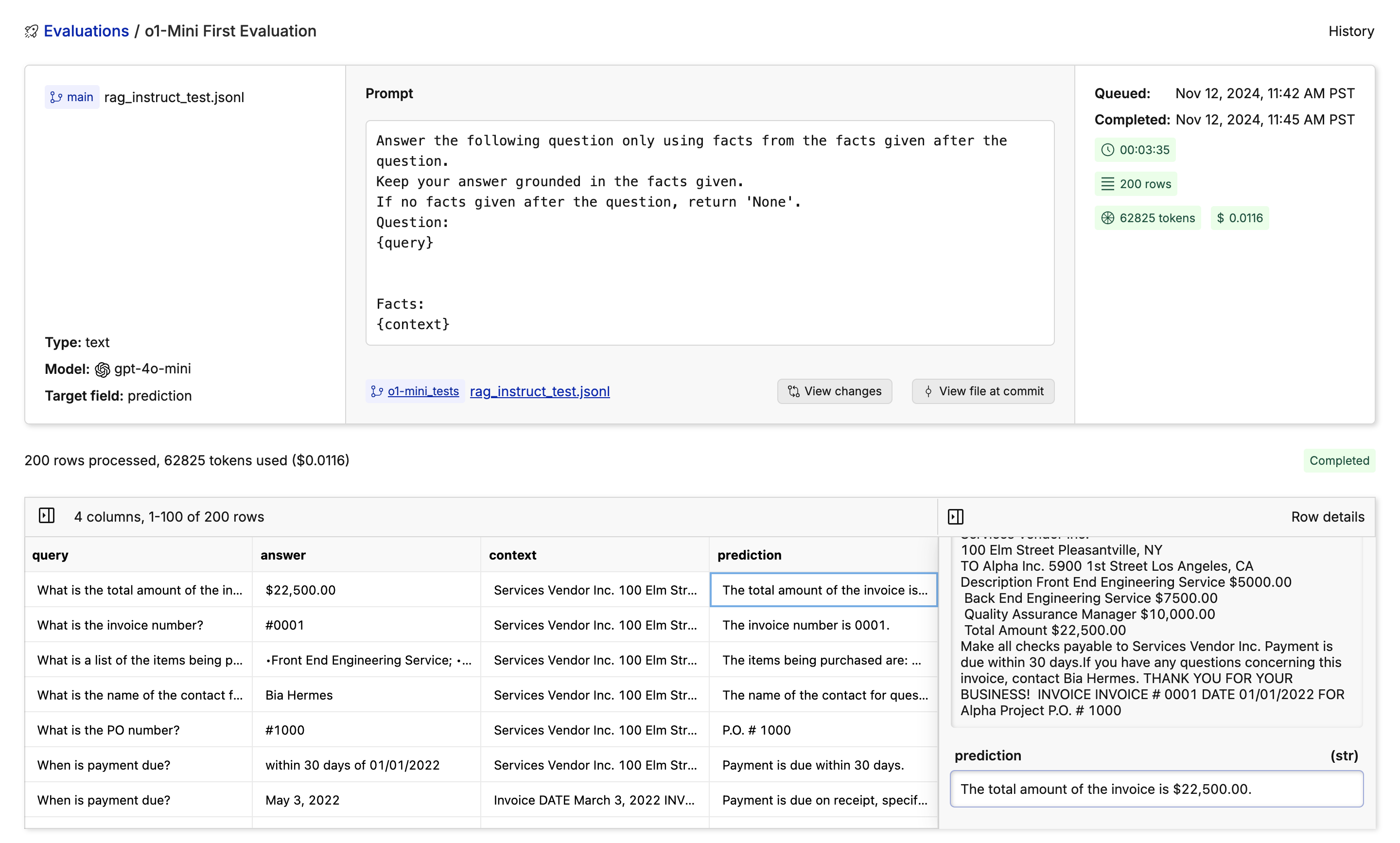
You will now find Oxen’s model evaluation feature. This is where you can choose a model, set up a prompt, and choose the output column. In this case, we are using OpenAI’s o1-Mini and passing in the question and data related to the question in the prompt: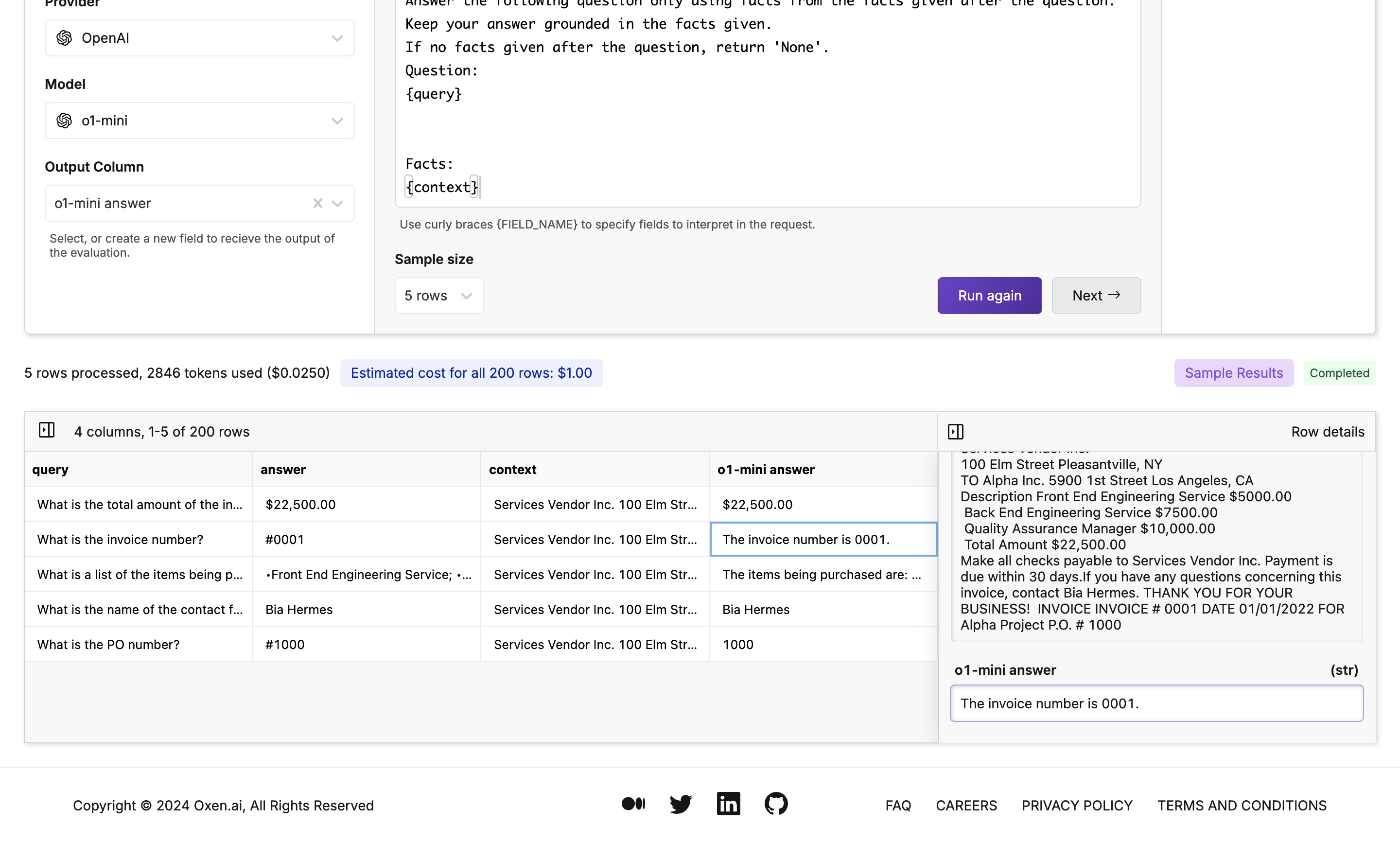
Select Your Destination
After clicking “Next” once your sample has been completed, you will see a commiting page. Here you will decide the target branch, target path, and if you would like to commit instantly or after reviewing the analysis. In this case, a new branch calledo1-mini_tests is being created and storing the changes. Once you’ve decided, click “Run Evaluation”.
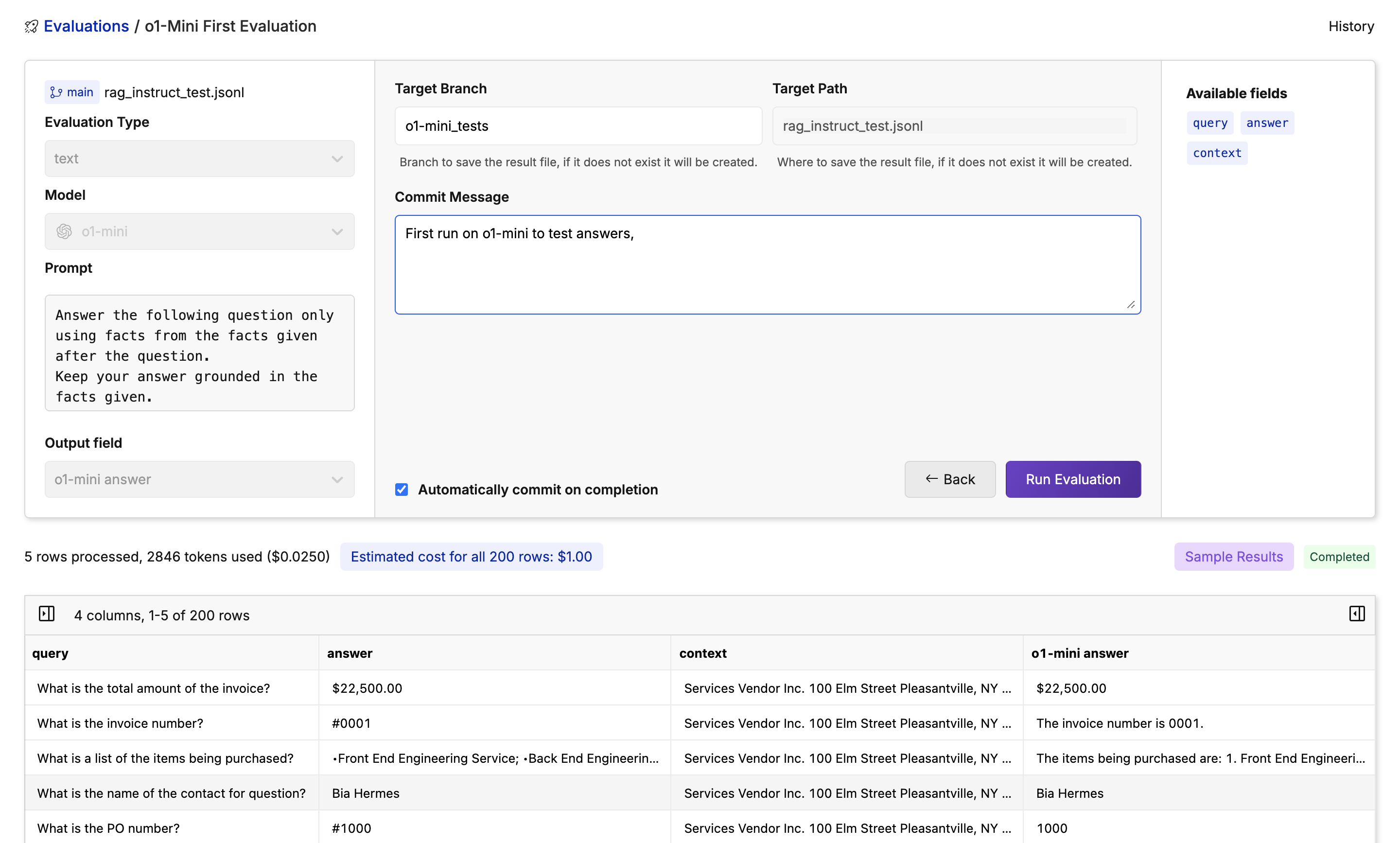
Monitor Your Evaluation
Feel free to grab a coffee, close the tab, or do something else while the evaluation is running. Your trusty Oxen Herd will be running in the background. While the evaluation is running you will see a progress bar showing how many rows have been completed, an update of how many tokens are being used, and how expensive the run is so far.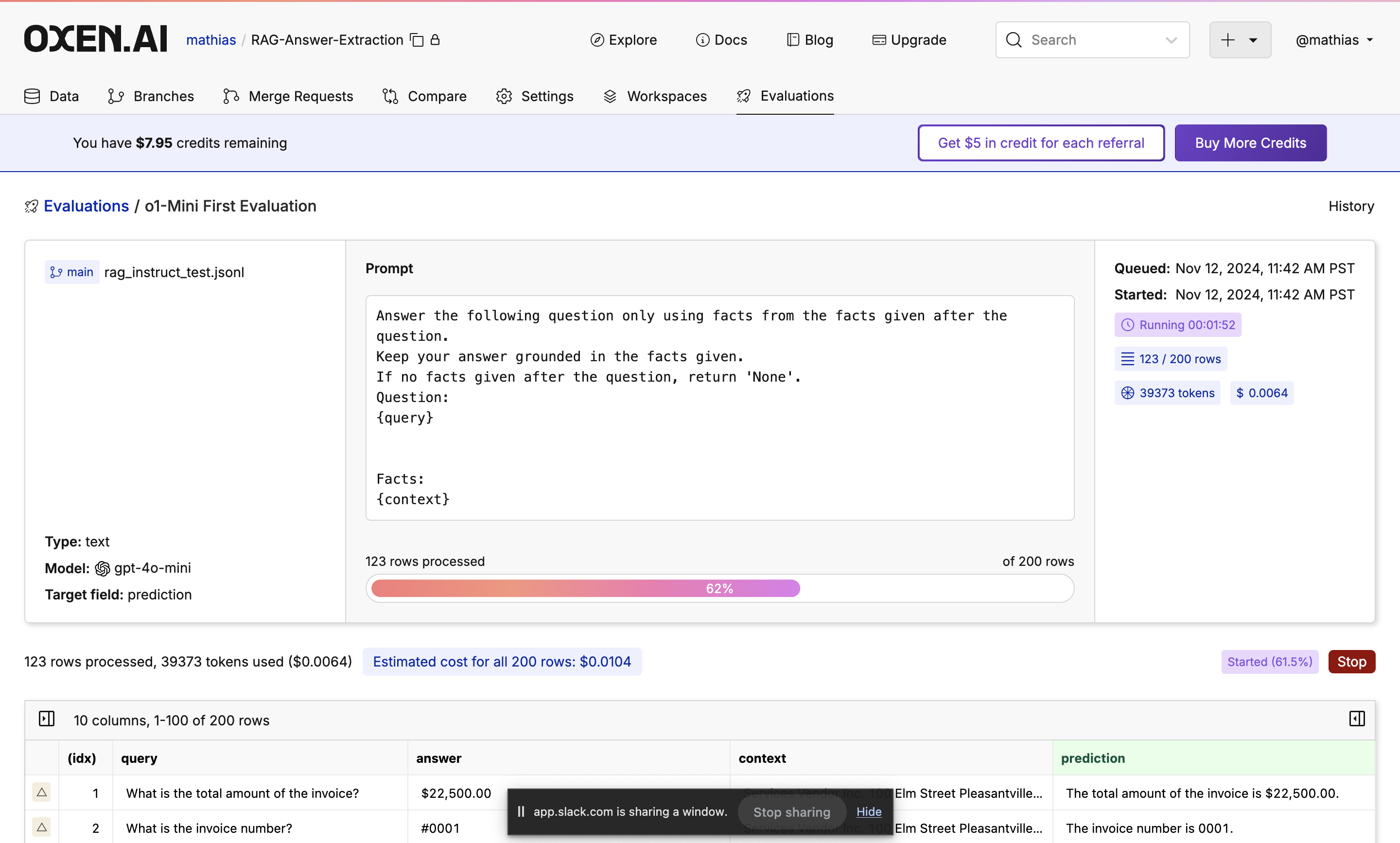
Next Steps
Once done, you will see your new dataset committed to the branch you specified. If you don’t like the results, don’t worry! Under the hood, all the runs are versioned so you can always revert to or compare to a previous version.