Our Data
In this repo, we’re comparing the outputs of the Gemma-2b-Instruct model and Llama-7b-chat-hf model on the Boolq Benchmark. Let’s check out the structure of these datasets:validation_response).
We can see here that our models didn’t output exactly “True” or “False” like they were told to. So we added a column processed_response to show a clean difference between the outputs.
Comparing Model Results
But we mainly care about how these models do compared to each other. So we basically want to know where theprocessed_response’s are different in each file.
View Results in Oxen UI
These results are also available in the Oxen UI, which makes it a bit easier to grok what’s going on than the command line.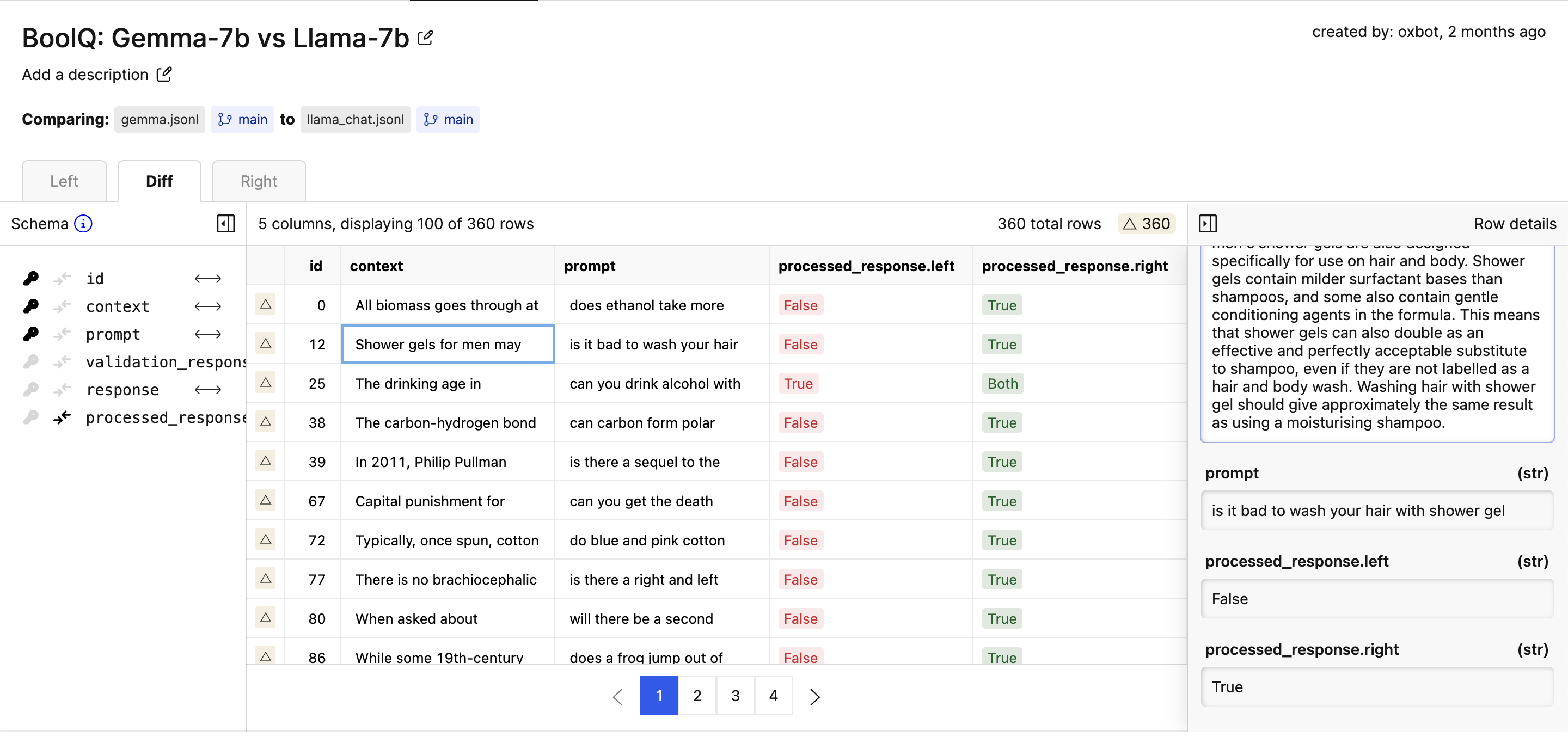
llama_chat in this case) didn’t really provide an answer, as it responded with both “True and False”.
Takeaways
Some potential takeaways are:- Gemma-2b was better at following these instructions (text formating) than Llama-7b despite its smaller size.
- These models were fairly in agreement on the validation set without any finetuning on the training set.
- Gemma-2b is a candidate to replace Llama-7b-chat as a base model for this task, however we will need to further explore to confirm.