Documentation Index
Fetch the complete documentation index at: https://docs.oxen.ai/llms.txt
Use this file to discover all available pages before exploring further.
🖼️ 1 Million Files Benchmark
When we first started working on Oxen.ai, we were inspired by making a tool that would make it easy to collaborate on large datasets that power modern AI research. One dataset that comes to mind is the original ImageNet dataset. This dataset spans 1000 object classes and contains > 1,000,000 training images and 100,000 test images. It commonly gets shared as a tarball, zip file, or gets dumped to S3 without much visibility into the data itself.
📊 The Raw Numbers
To create this benchmark, we took the 1 million+ images from ImageNet and added them to Oxen, DVC, Git-LFS, and S3. The total time is to get the files from A (local filesystem) to B (remote storage) successfully. The steps to reproduce and the machine specs are in the sections below. Here are the results in ranked order from fastest to slowest.| Tool | Time | Can view data? |
|---|---|---|
| 🐂 Oxen.ai | 1 hour and 30 mins | ✅ Yes |
| Tarball + S3 | 2 hours 21 mins | ❌ No |
| aws s3 cp | 2 hours 48 mins | ❌ No |
| DVC + Local | 3 hours | ❌ No |
| DVC + S3 | 4 hours and 51 mins | ✅ Yes w/ Other Tools |
| Git-LFS | 20 hours | ❌ No |
⚙️ Hardware and Network
All of the benchmarks were executed on at3.2xlarge EC2 instance with 4 vCPUs and 16.0 GB of RAM and a 1TB EBS volume attached. We found that the size of the EBS volume did impact the IOPs for adding and committing data for all tools. All of the network transfer was within us-west-1 within AWS to S3.
👀 View the Data
One of the other advantages of using Oxen.ai, besides raw speed, is that you can view, query and collaborate on the data as soon as you’ve pushed it to the web hub. Feel free to explore the end result here in Oxen.ai.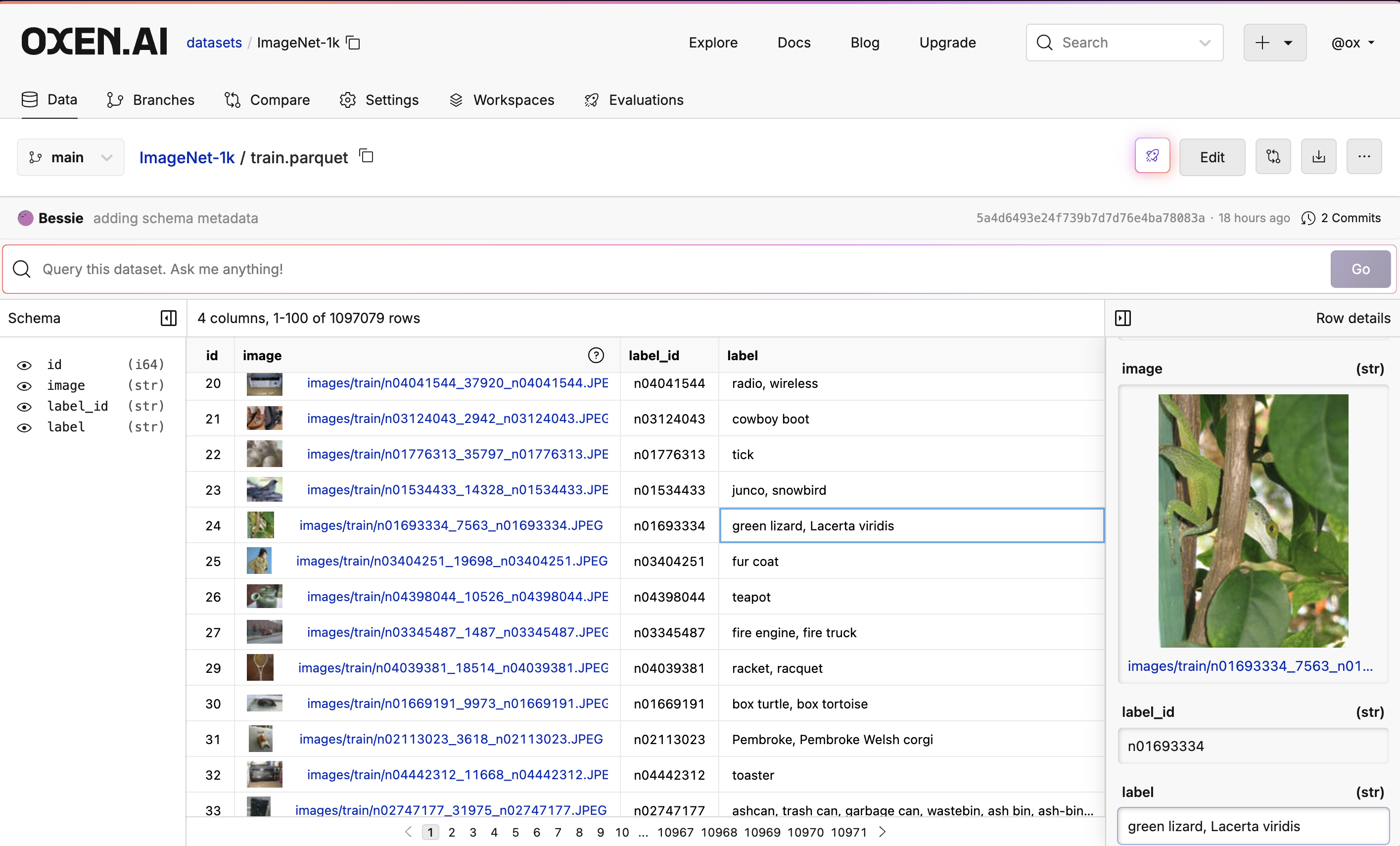
🧐 Why not Git?
Everybody knows and loves Git. But we also know that it isn’t exactly suited to version data. Trying to add multi-gigabyte datasets can quickly blowup storage costs and cause serious slowdown. And that isn’t really Git’s purpose, either - GitHub, for instance, doesn’t even accept files larger than 100 megabytes. Over the years, however, several attempts have been made to extend Git to gigabyte or even terabyte scale. In 2015 Git-LFS support was added to GitHub, which speeds up pulls by downloading files lazily, replacing tracked files with pointers and retrieving their content upon checkout. Data Version Control (DVC) came out in 2017, employing a similar concept but storing the file contents externally to Git. In theory it sounds great to tie your VCS to the most popular version control system in the world in git. But in practice, it is a bit like trying to fill a swimming pool with a straw. You can do it, but you are tied to the limitations of the git protocols.🐂 How does Oxen.ai work?
With Oxen.ai, we take a different approach. Rather than trying to extend Git, we built Oxen, taking inspiration from Git where we can. We didn’t want to make you learn a completely new tool. If you know how to use git, you know how to use Oxen. But we also designed Oxen specifically to make versioning large amounts of data as fast as possible. Under the hood, Oxen uses Merkle trees, smart network protocols and fast hashing algorithms to reduce the amount of data our repositories store. Unbound by Git, however, we’re also able to employ several other optimizations that make Oxen fast such as block-level deduplication, compression, iterating on subtrees, and more. Some of these optimizations are still under development, but we’re excited to share what we have so far, and you can find a deeper dive and list of the upcoming features here. All of the code is open source and available on GitHub. We appreciate any feedback you have and welcome any stars and contributions!🏃 Running the Experiments
To give you a sense of the process as well as point out the advantages & challenges associated with each method, we ran the following experiments below, listed from slowest to fastest.Git + LFS (~20 hours)
Git-LFS is a popular first tool to try since it is already in the Git ecosystem. The problem is that it is painfully slow when it comes to adding, committing, and pushing non-text files. It can also be a bit annoying to remember which files are tracked under LFS vs just regular Git. Many times have I accidentally committed a multi-GB file to git and wondered why my push was taking so long. Removing files from the git merkle tree is a whole other pain. Steps to reproduce:20+ hours
Adding and committing data locally is not terribly slow (still slower than Oxen). But it does have to hash and copy every file into the hidden .git directory. The combination of using a slow hashing algorithm and copying large files makes git-lfs slower than it has to be on add and commit.
The real killer here though is the push 🥱. Pushing data to the remote takes over 20 hours in the case of ImageNet, even on the same network as our other tests.
DVC + S3 Backend (~5 hours)
DVC is a popular tool, tightly integrated with the Git ecosystem and can be configured for multiple storage backends. You’ll see that you have to toggle back and forth between DVC and git with 11 commands to remember and execute. It is easy to make a mistake and track the wrong things in your git repo as well as simply wrap your head around the fact that you are using two different tools to version your data. Steps to reproduce:4 hours and 51 mins
As you can see, DVC is not as slow as Git-LFS, but it is significantly more commands to remember and execute.
DVC + Local Storage Backend (~3 hours)
We wanted to do another test with DVC without any network transfer, purely to test the protocol overhead. Transferring to S3 may not be the best apples to apples comparison, since Oxen also compresses and deduplicates data on the network transfer.3 hours
As we’ll see below, Oxen is faster than DVC even if you drop the overhead of network transfer.
Tarball + S3 (~2 hours 21 mins)
I like to call this one, “F’ it, let’s just create a tarball and upload it to S3”. Easy to remember, easy to use, but not very efficient nor effective when it comes to iterating on data.2 hours 21 mins
This may work well for cold storage of data you may rarely want to view again. But for anything else, Oxen is a much better tool.
Oxen smartly compresses and creates smaller data chunks behind the scenes while transferring your data across the network, taking advantage of the network bandwidth and reducing the amount of time it takes to upload and download data.
aws s3 cp (~2 hours 48 mins)
You may be asking yourself, well if the tarball takes so long to create, why not just use theaws s3 cp command with the --recursive flag?
2 hours 48 mins
This is a bit slower overall than the tarball method, and you still have the same problems of iterating on and viewing the data. By looking at the logs, it looks like the s3 sdk is syncing the files one by one, which accounts for the slowness.
Oxen.ai (~1 hour and 30 mins)
With Oxen, if you know how to use git, there are no extra commands to remember. With the same commands as plain old git you can initialize, add, commit, and push your data to the remote. Steps to reproduce:1 hour and 30 mins
If you are curious how Oxen works under the hood, we are working on a detailed technical writeup that dives into the Merkle tree, block-level deduplication, and more here.