Documentation Index
Fetch the complete documentation index at: https://docs.oxen.ai/llms.txt
Use this file to discover all available pages before exploring further.
Say you are working with a dataset with 100GB of images, you may want to contribute back to the dataset, or only need a small subset of the data to run a model. In these cases, it doesn’t make sense to download the entire dataset locally. Instead, you can use partial clones.
Oxen has three main ways of interacting with subsets of your data.
- Partial Clones - Clone a subtree of the data in your repository to a local working directory.
- Download Read Only - Download a read only copy of the subset to your local machine.
- Remote Workspaces - Interact with your data all server side, no files are downloaded locally.
Each of these methods has it’s own benefits and trade offs. We will go over each of them in more detail below.
Partial Clones
The first command line parameter you should be aware of is the --filter flag. This flag is inclusive for the paths you want to clone.
oxen clone https://hub.oxen.ai/ox/Flowers --filter "images/roses"
images/roses directory into a local working directory. Under the hood, it also creates a .oxen directory which contains the merkle tree for the cloned data, and content addressable copies of each file in the subtree.
 You can also specify a depth parameter to control how deep the clone is. If you have many nested subdirectories, you can use the
You can also specify a depth parameter to control how deep the clone is. If you have many nested subdirectories, you can use the --depth flag to limit how deep the clone goes.
oxen clone https://hub.oxen.ai/ox/Flowers --filter "." --depth 1
Download Read Only
If you have no intention of making any changes to the data, the easiest way to interact with a subset is to download a read only copy. This can be done with the oxen download command.
oxen download ox/Flowers images/roses
 This is the most efficient way to download data if you are simply going to read the data or throw it away later.
This is the most efficient way to download data if you are simply going to read the data or throw it away later.
Remote Workspaces
You may not need a local copy of the data at all. If you are working with a remote dataset, you can interact with it all server side.
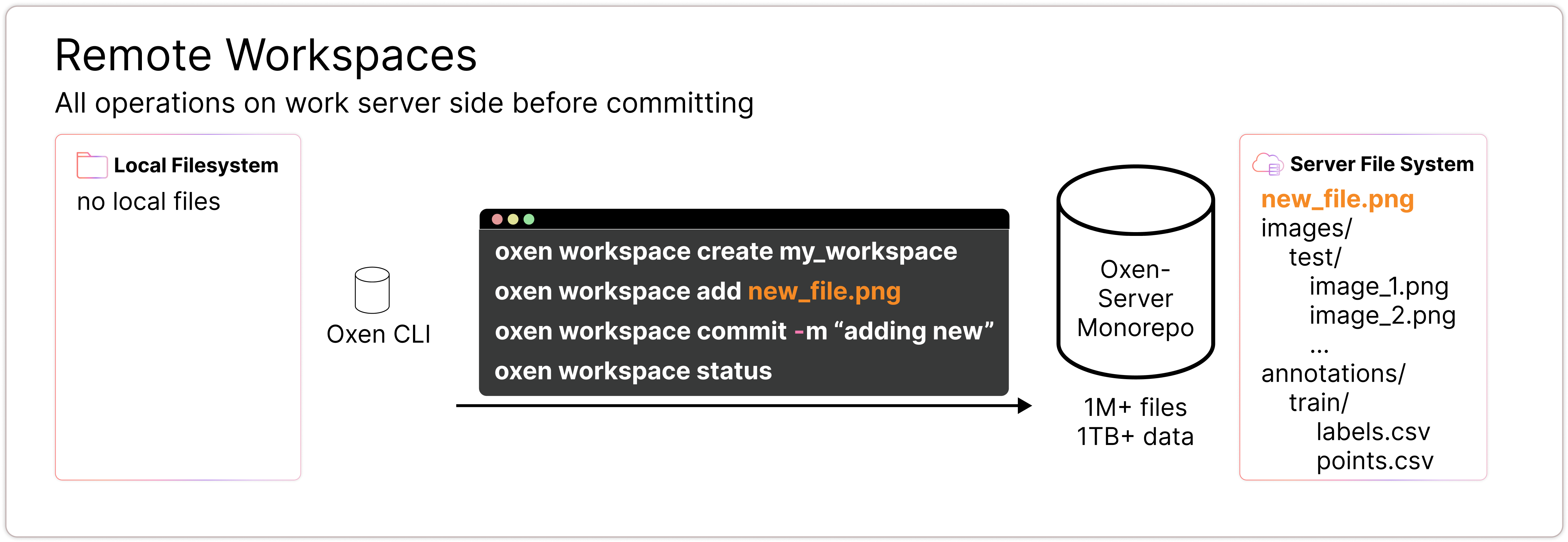 Conceptually you can think of a workspace as a server side working directory where you can stage changes before committing them. Under the hood, a workspace is tied to a commit id. This means whatever changes you make will always be with respect to the commit you created the workspace off of.
Conceptually you can think of a workspace as a server side working directory where you can stage changes before committing them. Under the hood, a workspace is tied to a commit id. This means whatever changes you make will always be with respect to the commit you created the workspace off of.
Instantiating a Workspace
A workspace is created off of a RemoteRepo and a branch name. The branch name is just a convenience for the user to create a workspace on the underlying commit id.
from oxen import RemoteRepo
from oxen import Workspace
repo = RemoteRepo("ox/CatDogBBox")
workspace = Workspace(repo, "add-images")
main).
from oxen import RemoteRepo
from oxen import Workspace
repo = RemoteRepo("ox/CatDogBBox")
workspace = Workspace(repo)
Adding Files
When adding data, it is always a good idea to create a branch for the changes you are about to make. This will allow you to commit changes without affecting the default branch.
Creating a Branch
from oxen import RemoteRepo
repo = RemoteRepo("ox/CatDogBBox")
# Create the branch on the remote
repo.create_branch("add-images")
# Make sure you are pointing to this branch
repo.checkout("add-images")
Uploading Files
Workspaces allow you to upload files without immediately committing them. Think of this as a staging area where you can upload the data, and then batch commit when you are ready.
from oxen import RemoteRepo
from oxen import Workspace
repo = RemoteRepo("ox/CatDogBBox")
workspace = Workspace(repo, "add-images")
workspace.add("/path/to/image.png")
status = workspace.status()
print(status.added_files())
Removing Uploaded Files
If you accidentally add file from the remote workspace and want to remove it, no worries, you can unstage it with oxen remote rm --staged.
from oxen import RemoteRepo
from oxen import Workspace
repo = RemoteRepo("ox/CatDogBBox")
workspace = Workspace(repo, "add-images")
workspace.rm("image.jpg")
status = workspace.status()
print(status.added_files())
Commit Changes
When you are confident in the changes you have made, you can commit the changes to the remote workspace. This will create a new commit on the remote branch.
from oxen import RemoteRepo
from oxen import Workspace
repo = RemoteRepo("ox/CatDogBBox")
workspace = Workspace(repo, "add-images")
workspace.commit("adding an image", "add-images")