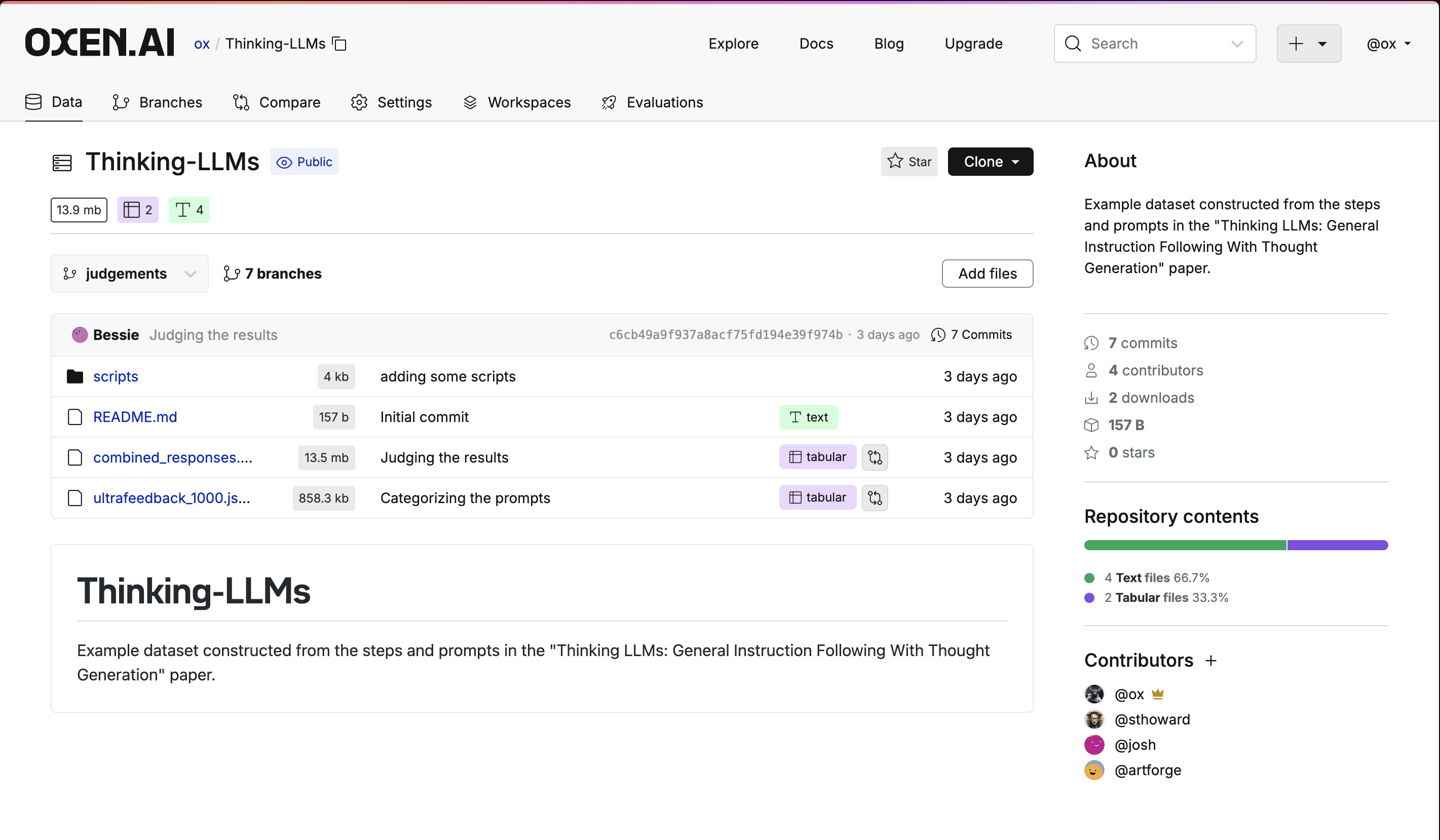
Upload Your Data
You can either upload data directly to a repository using the web interface or CLI. On the web, simply click theAdd Files button in the repository and select your file.
oxen add command.
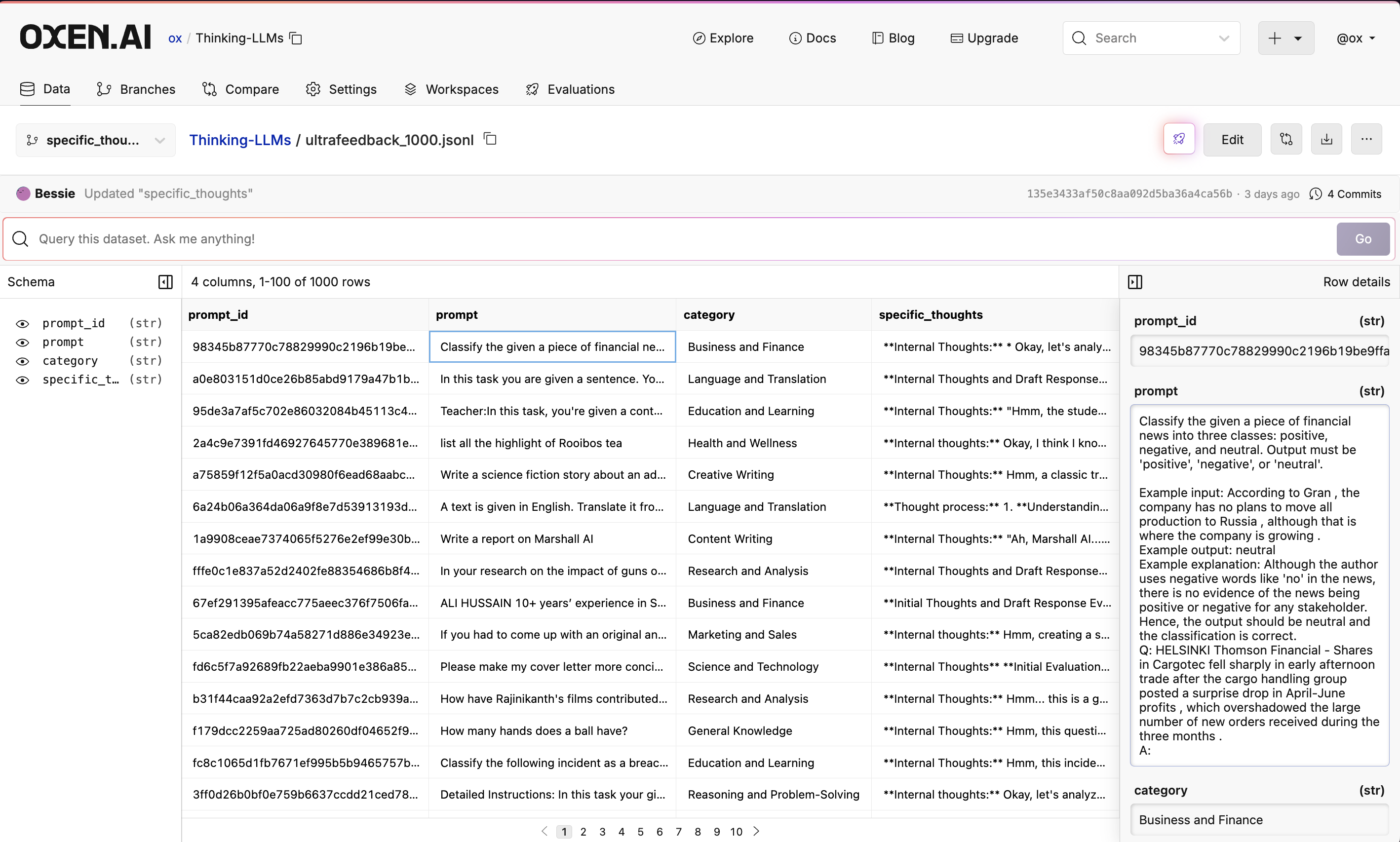
Look At Your Data
Oxen.ai makes it easy to look at your data in a tabular format. When files are committed to a repository, Oxen automatically detects the format of your data and loads it into a DataFrame if it is acsv, tsv, parquet, json, jsonl, ndjson, or arrow file. Behind the scenes, Oxen uses the Polars library to load your data in a performant and efficient manner.
Query Your Data
All Oxen data frames can be queried with SQL. When using the UI, we also provide a Text2SQL interface to help you get started. We automatically translate natural language questions into SQL queries and return the results in a tabular format.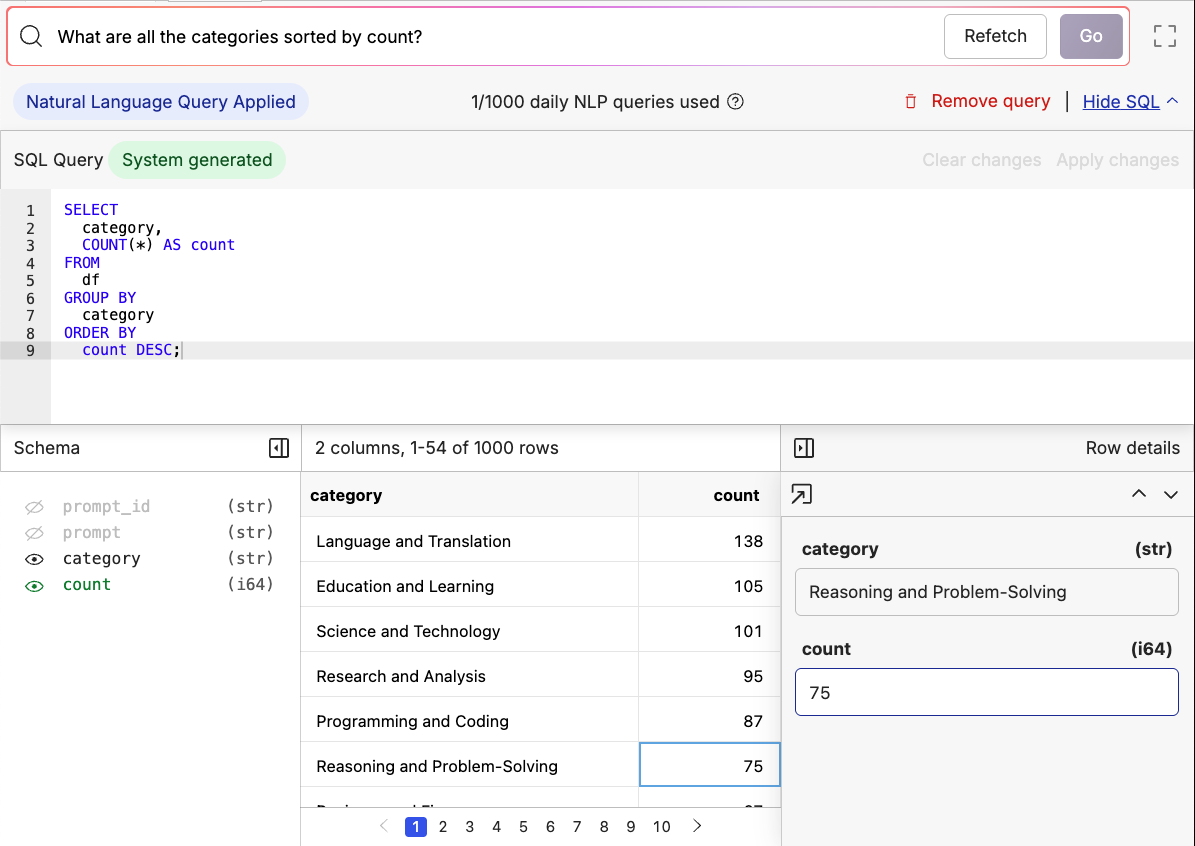
Edit Your Data
You can also edit data frames directly in the UI. Double click on a cell to edit it, and use the buttons in the side panel to add, delete, and modify rows. You can also rename columns, add new columns, and remove columns.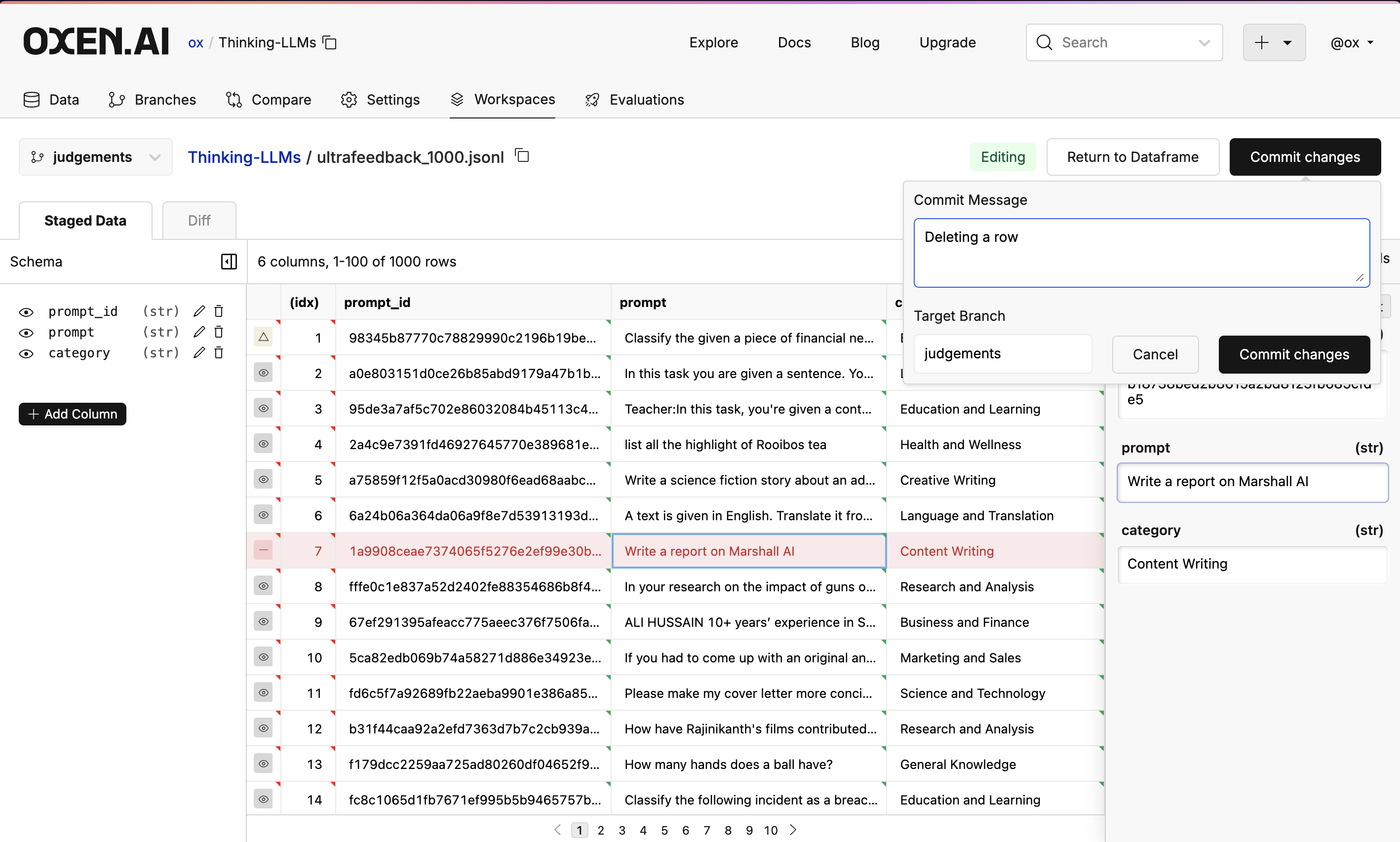
Commit button in the top right.
Oxen CLI
Oxen also provides command line tools to interact with data frames. This makes it easy to manipulate data files before committing them to the repository.oxen df
oxen df is a handy subcommand to interact with data frames locally. For example, oxen df <FILENAME> displays the contents of tabular data files.
--full flag.
You can also use oxen df options to view your data with modifications. These changes won’t be written anywhere unless you use the --write or --output flags.
Uploading Data
Before modifying your data, add it to a repository to preserve its history. This can be done in the UI, Python, or CLI.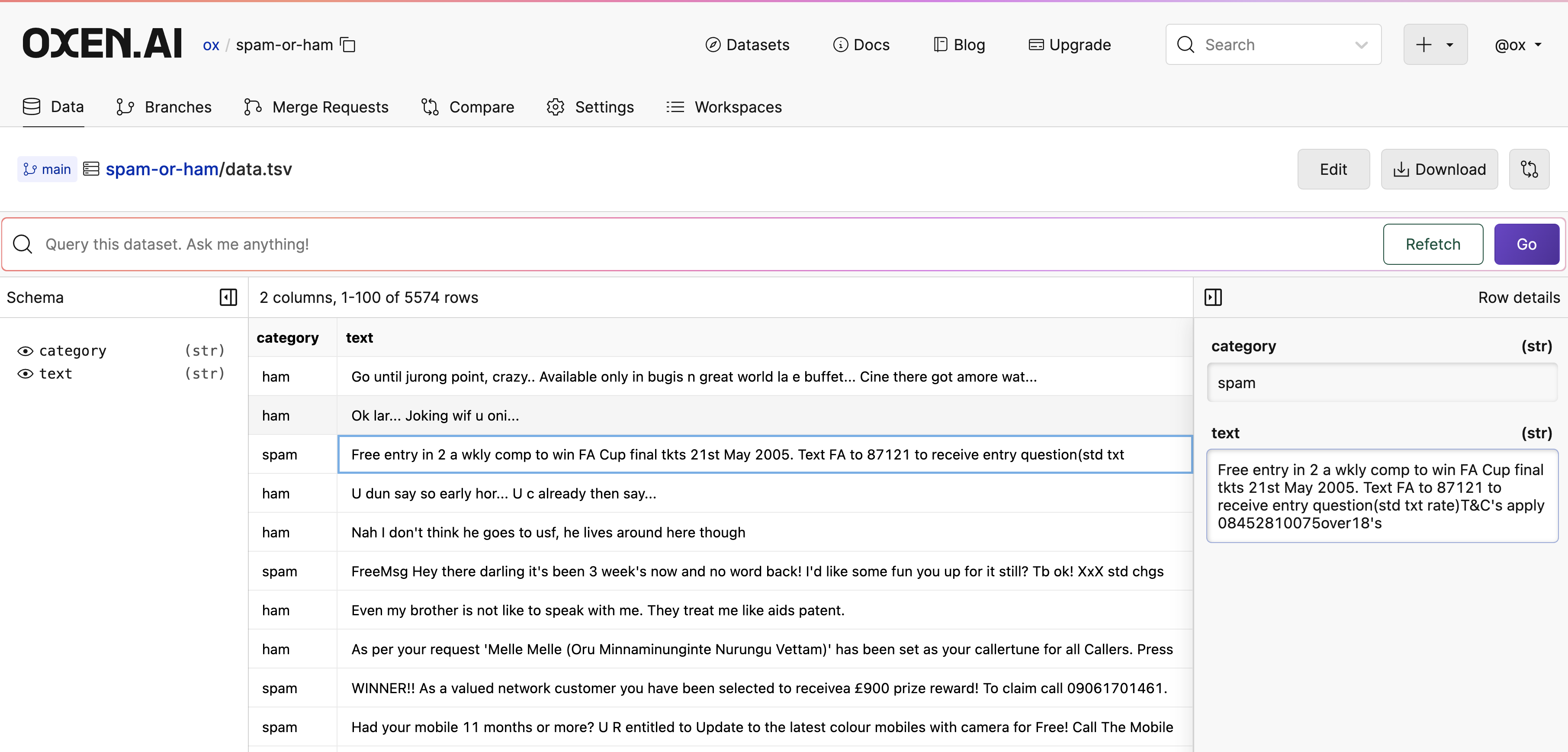
Editing Data Frames
Once you’ve added your data to an Oxen repository, you can interact with data frames even if they’re not downloaded locally. Oxen exposes a CRUD interface that makes this possible.oxen df --write. Any modifications you make with this flag set will be written back to the original file and register as ‘modified’ in your Oxen repository.
Useful Commands
There are many ways you might want to view, transform, and filter your data on the command line before committing changes to the dataset.oxen df provides several options that can help with this.
For these examples, we’ll use our CatDogBBox repository.
Convert Dataset Format
Oxen allows you to quickly transform data files between data formats. When you runoxen df with --output, the resulting data frame will be written to disk as a new file of the specified type.
Some formats like parquet and arrow are more efficient for different tasks, but are not human readable like tsv or csv. These are tradeoffs you’ll have to decide on for your application. Oxen currently supports the following file extensions: csv, tsv, parquet, arrow, json, jsonl.
SQL Query
Oxen has a powerful SQL query engine built in to the CLI. You can run SQL queries on your data frames with the —sql flag.Filter
If you don’t need a full sql query, Oxen also has a lightweight--filter option which supports >, <, and == operations
View Schema
Oxen automatically detects and versions the schema of your data frame. See the schema docs for more information about this. To view a data frame’s schema in full, you can use the--schema flag.
View Specific Columns
If you only need a subset of your data frame’s columns, you can specify them in a comma separated list with--columns.
Take Indices
You can also view particular rows using--take
Unique
Oxen can efficiently compute all the unique values of a given column or set of columns using the--unique option.
Concatenate (vstack)
If you’ve filtered down your data and want to stack it back into a single frame. The--vstack option takes a variable length list of files you’d like to concatenate.
Add Column
Your data might not match the schema of a data frame you want to combine with, in which case you may need to add a column to match it. You can do this and project default values with--add-col 'col:val:dtype'
Add Row
You can also append new rows to the data frame. The--add-row option takes in a comma separated list of values and automatically parses the correct dtypes.
Randomize
Often, you’ll want to randomize data before splitting into train and test sets, or just to peek at different data values. This can be done with the--randomize flag.
Sort
You can sort your data with thesort flag. You can sort the data by the values of any column in your data frame.
Reverse
You can also reverse the order of a data table. By default--sort sorts in ascending order, but this can be switched with the --reverse flag.