Why Fine-Tune?
Fine-tuning is a great tool to reach for when basic prompting and context engineering fall short. You may need to fine-tune when:- Quality is critical and the model isn’t consistently producing correct outputs.
- Proprietary Data gives you a unique advantage that generic models can’t capture.
- Latency is a deal breaker and you need real-time responses.
- Throughput limitations are bottlenecking your application’s scalability.
- Ownership of the model is important and you want to control your own destiny.
- Cost if a foundation model is too expensive for your use case or you want to deploy a smaller model to the edge.
Modalities
Oxen.ai supports many data types and tasks for fine-tuning.Text Generation
Fine-tune a model to take a user input as text and generate a single response as text.
Chat Completions
Fine-tune a model on chat messages to have a conversation with a user.
Image Generation
Fine-tune a model to go from text descriptions to images.
Image Editing
Fine-tune a model to take a prompt and a reference image and generate a new image.
Video Generation
Fine-tune a model to take in a prompt and generate a video.
Start by Uploading a Dataset
To get started, you’ll need to create a new repository on Oxen.ai. Once you’ve created a repository, you can upload your data. The dataset can be in any tabular format includingcsv, jsonl, or parquet.
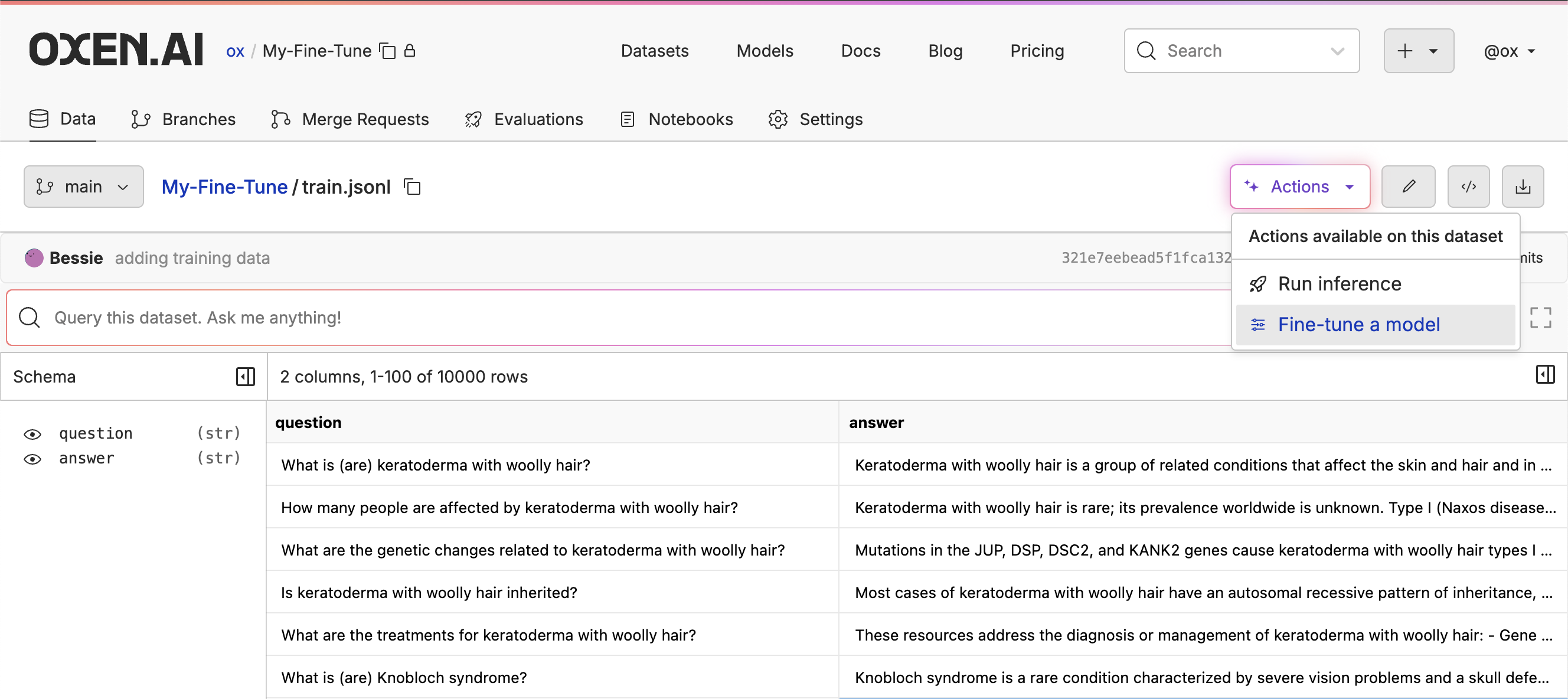
Selecting a Model
This will take you to a form where you can select the model you want to fine-tune and the columns you want to use for the fine-tuning process. We support fine-tuning for text generation, image generation, image editing, and video generation with a variety of models.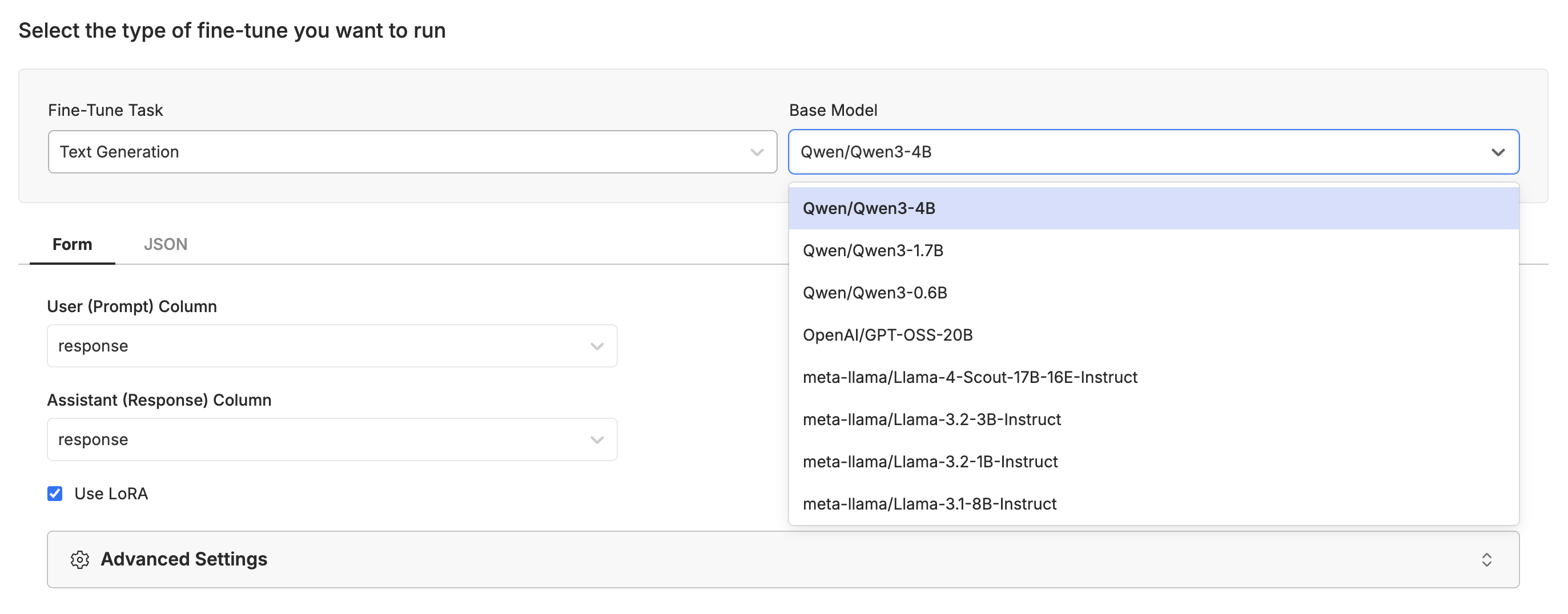
If you want support for any specific models, data formats, training methods contact us at hello@oxen.ai and we are happy to help you get started. We are actively working on support for new models and distributed training.
Monitoring the Fine-Tune
Once you have started the fine-tuning process, you can monitor its progress. The dashboard will show you loss over time and token accuracy processed.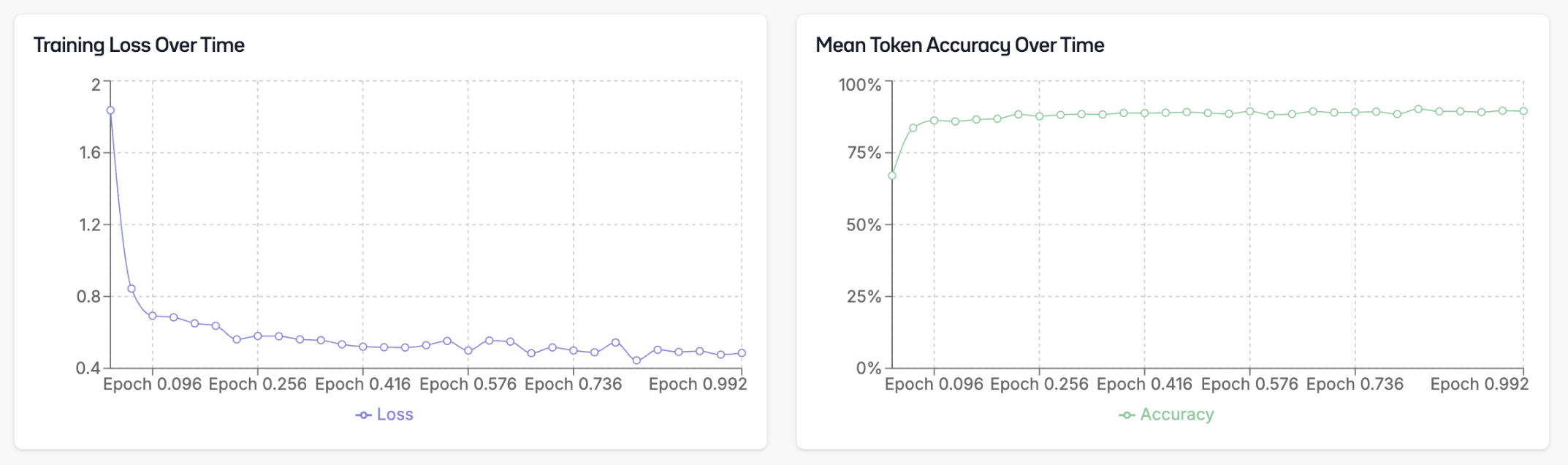
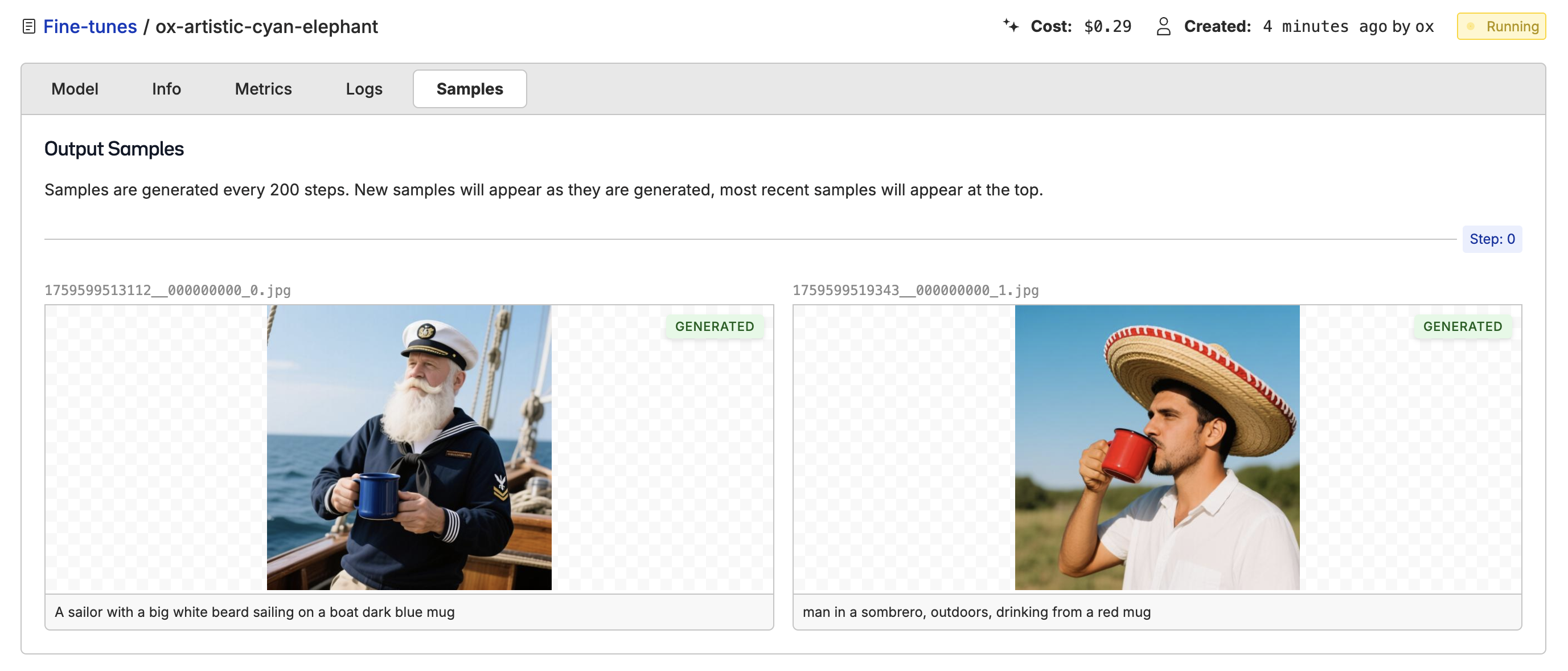
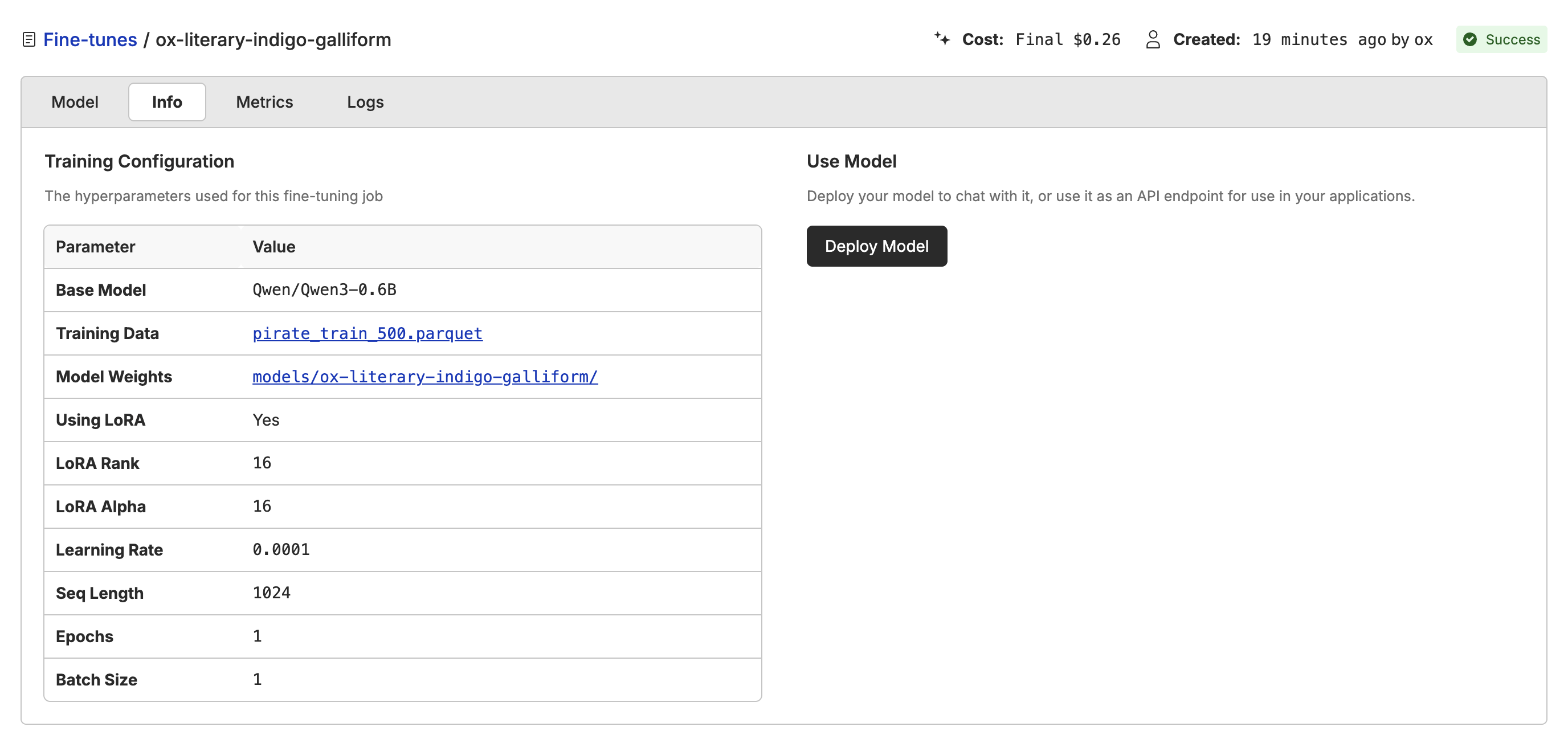
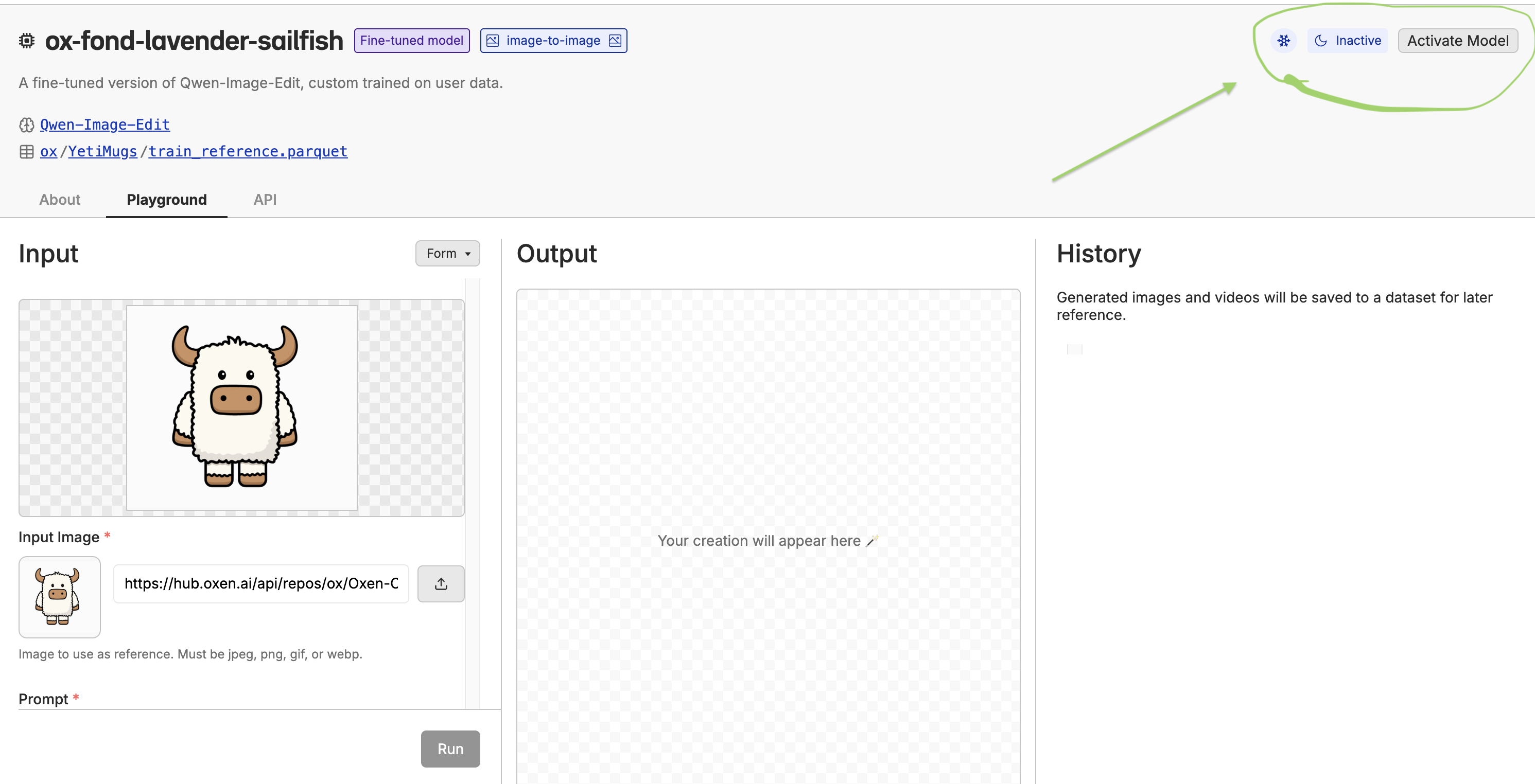
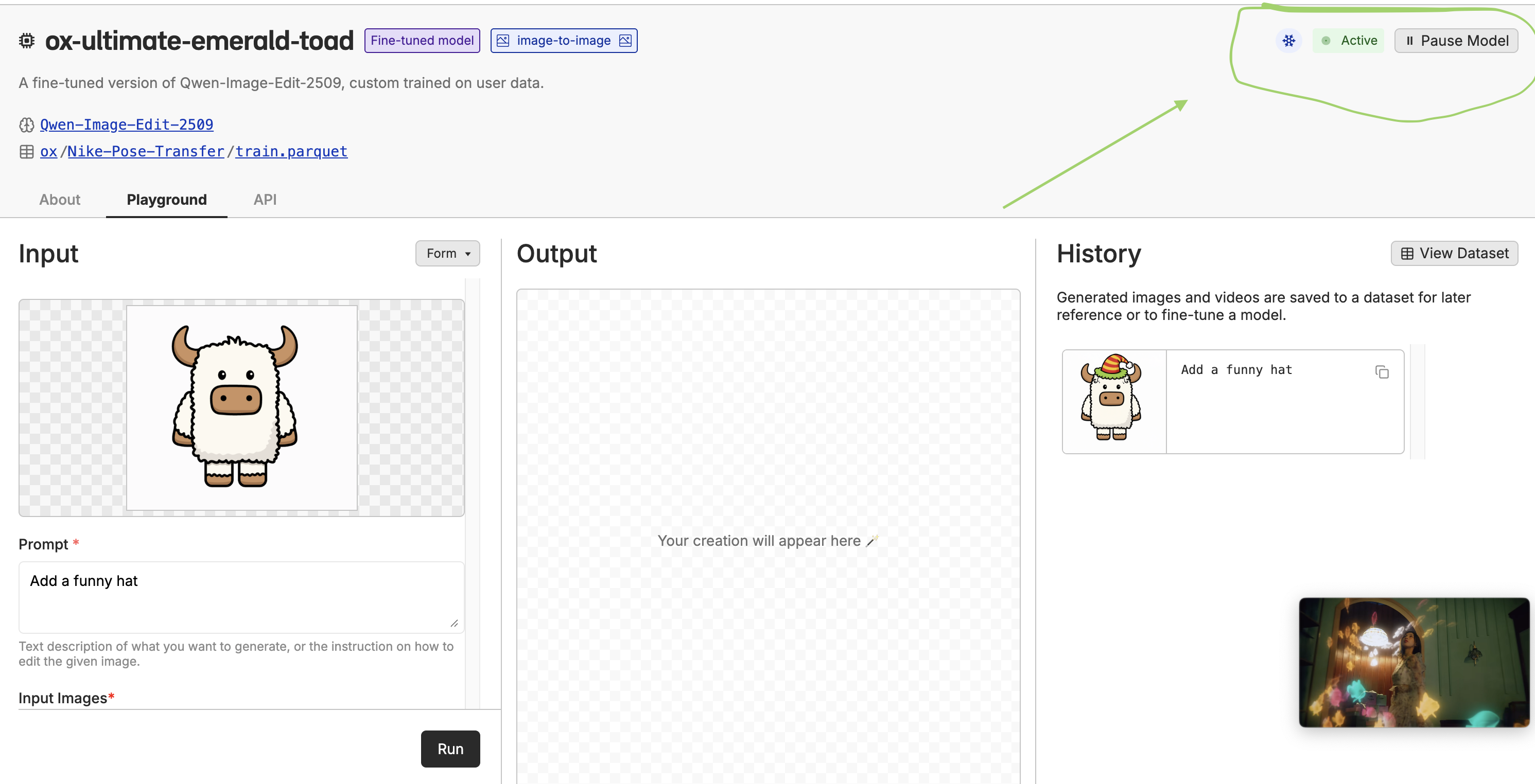
Deploying the Model
Once the model is fine-tuned, you can deploy it to a dedicated endpoint or in the playground. This will give you a/ai/chat/completions api and a playground that you can use to test out the model.
Start by using the “playgroud” button.

Using the Model
Once the model is deployed, you can also chat with it using the Oxen.ai chat interface at the playgroud. Learn more about the chat interface here.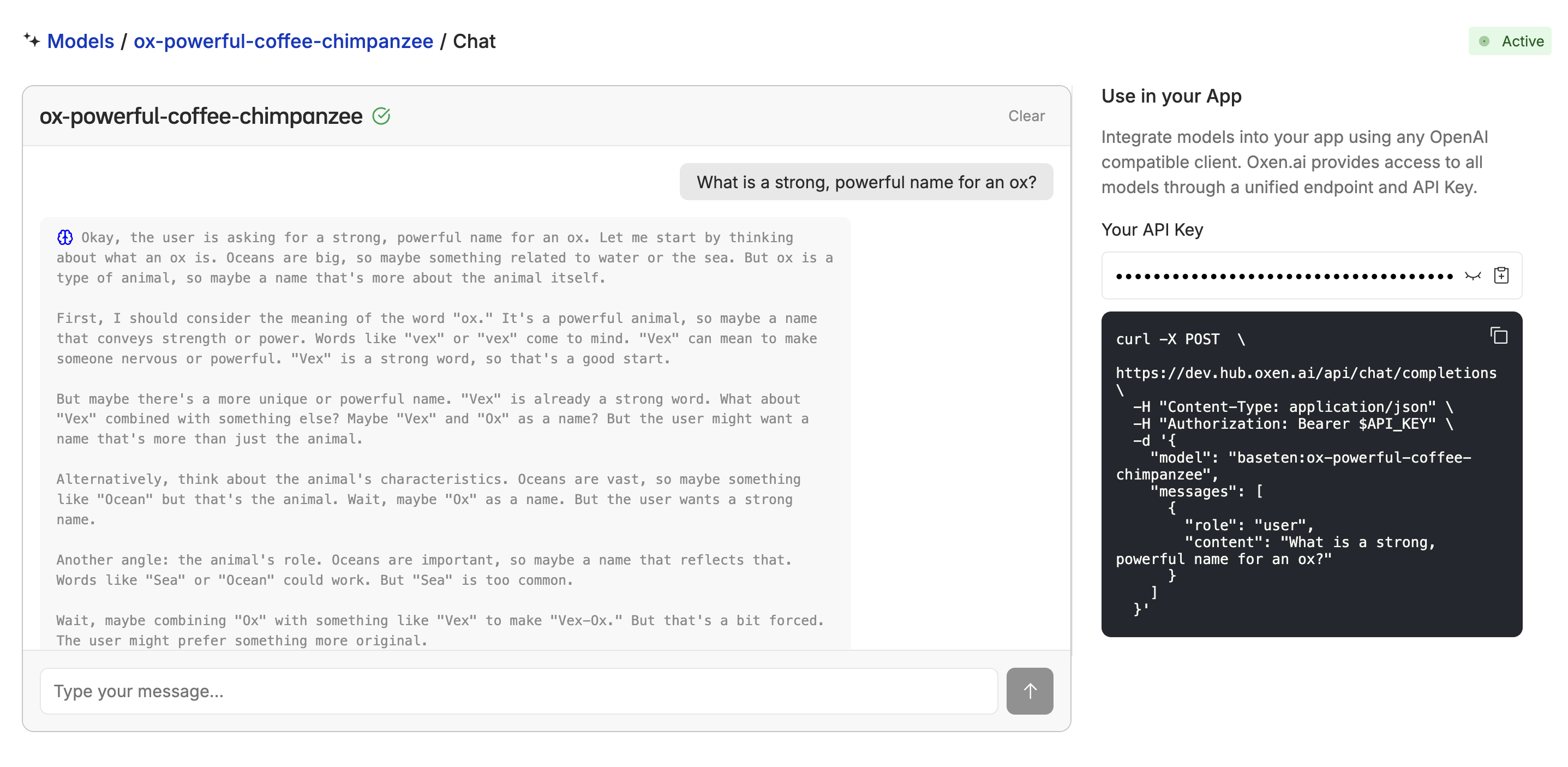
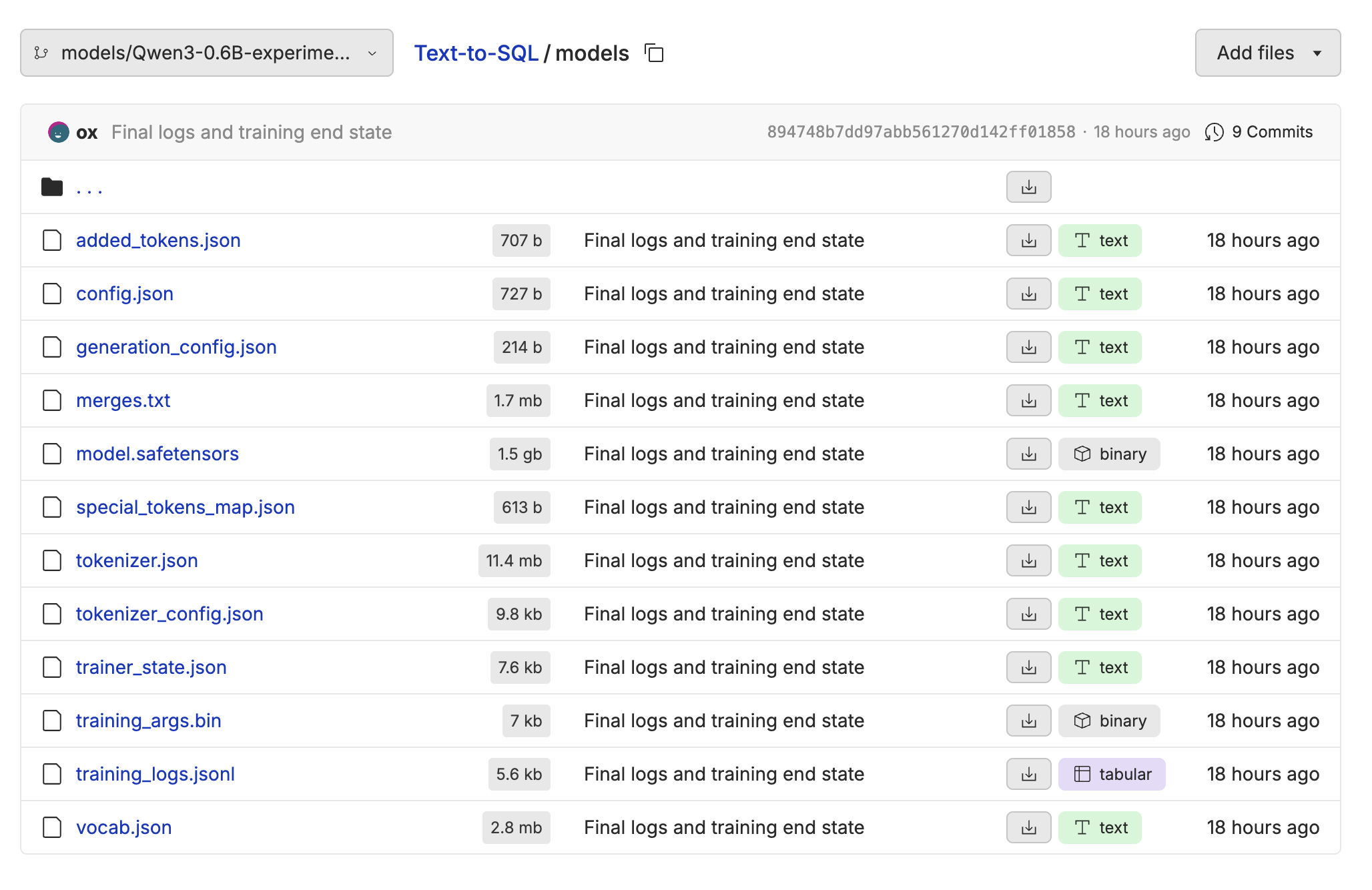
Downloading the Model
If you want access to the raw model weights, you can download them from the repository using the Oxen.ai Python Library or the CLI. Follow the instructions for installing oxen if you haven’t already.