In addition to simplifying your fine-tuning pipeline, Oxen.ai offers fine-tuning consultations and services if you are struggling with training a production-ready model. Sign up here to set up a meeting with our ML experts.
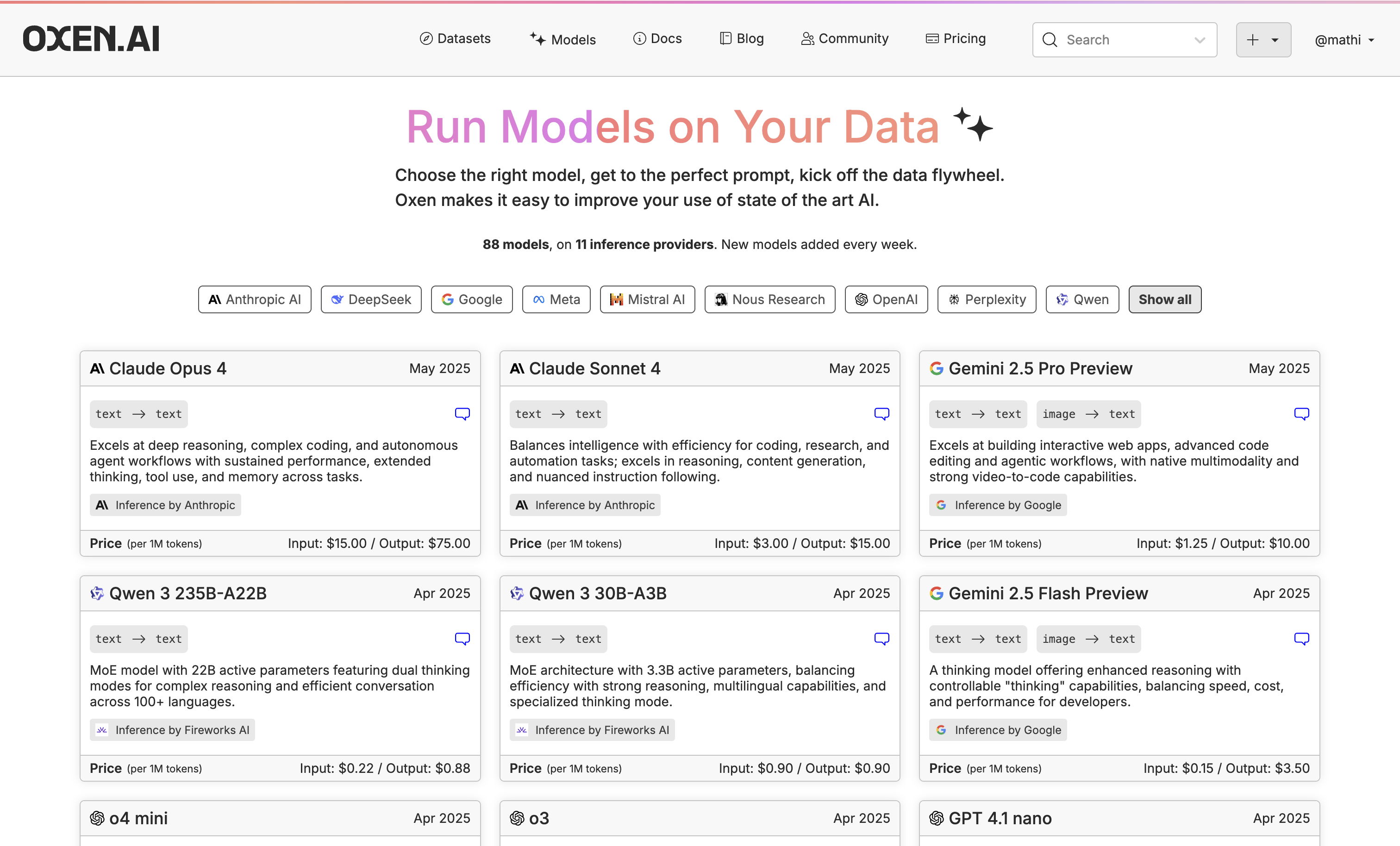
1. Test Different Small Models
2. Upload or Create Your Dataset
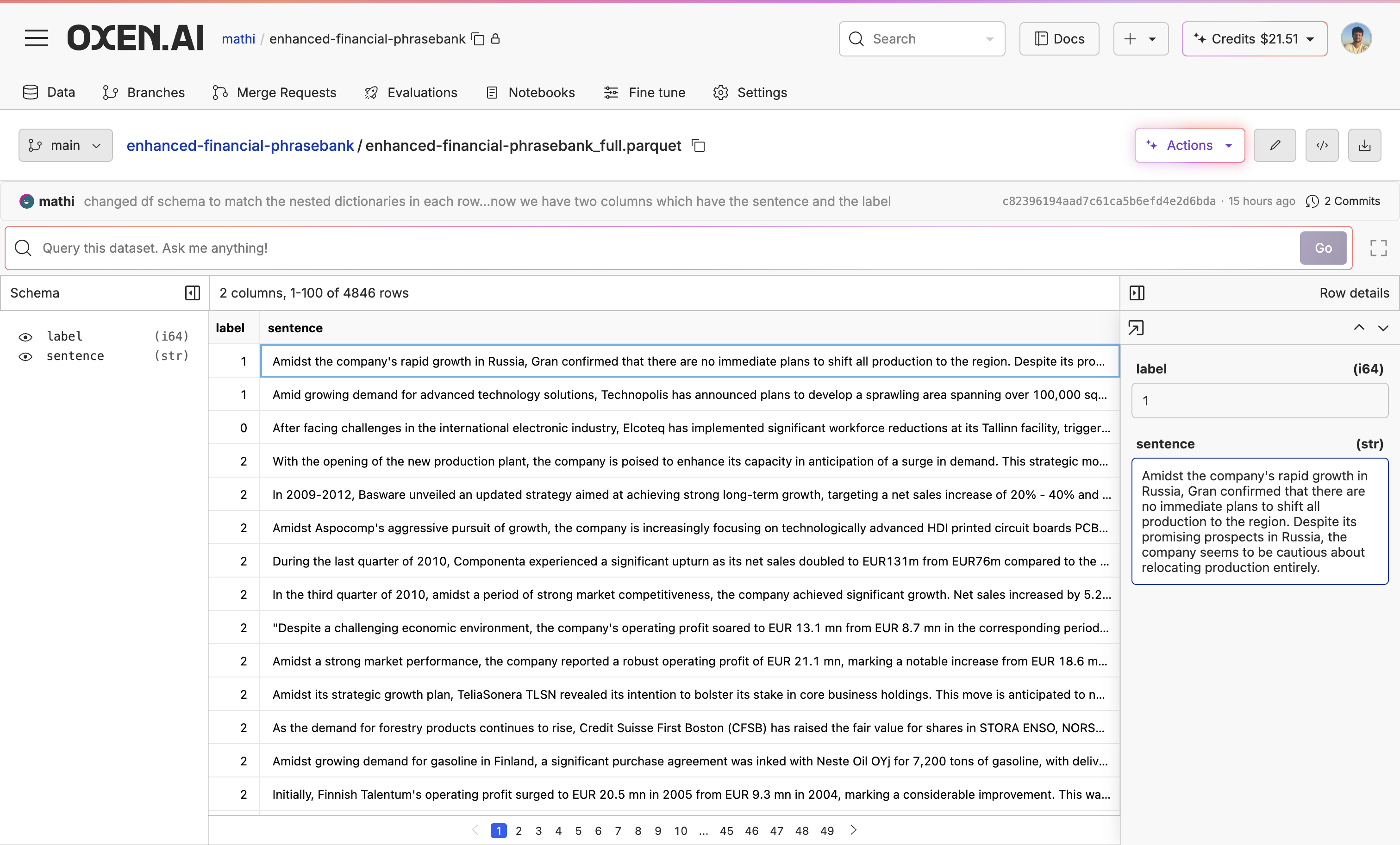
Once you have found a model you like, upload or create a dataset to fine-tune the model on. If you do not already have a dataset, you can explore new datasets and augment the data with our Model Inference tool. You can also use our Model Inference tool to generate synthetic data from scratch. If you already have a dataset, you can upload it easily with Oxen.ai’s CLI commands.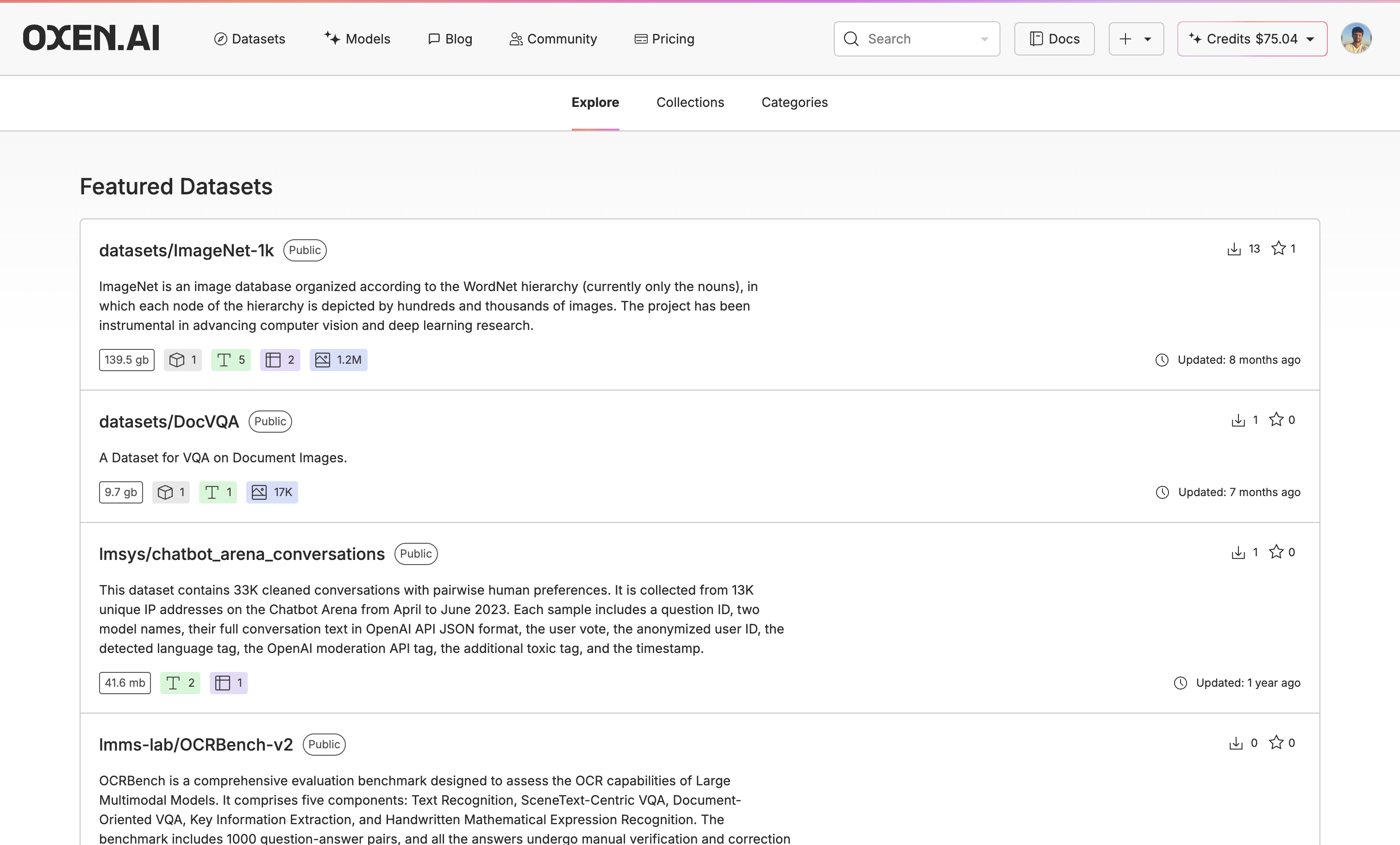
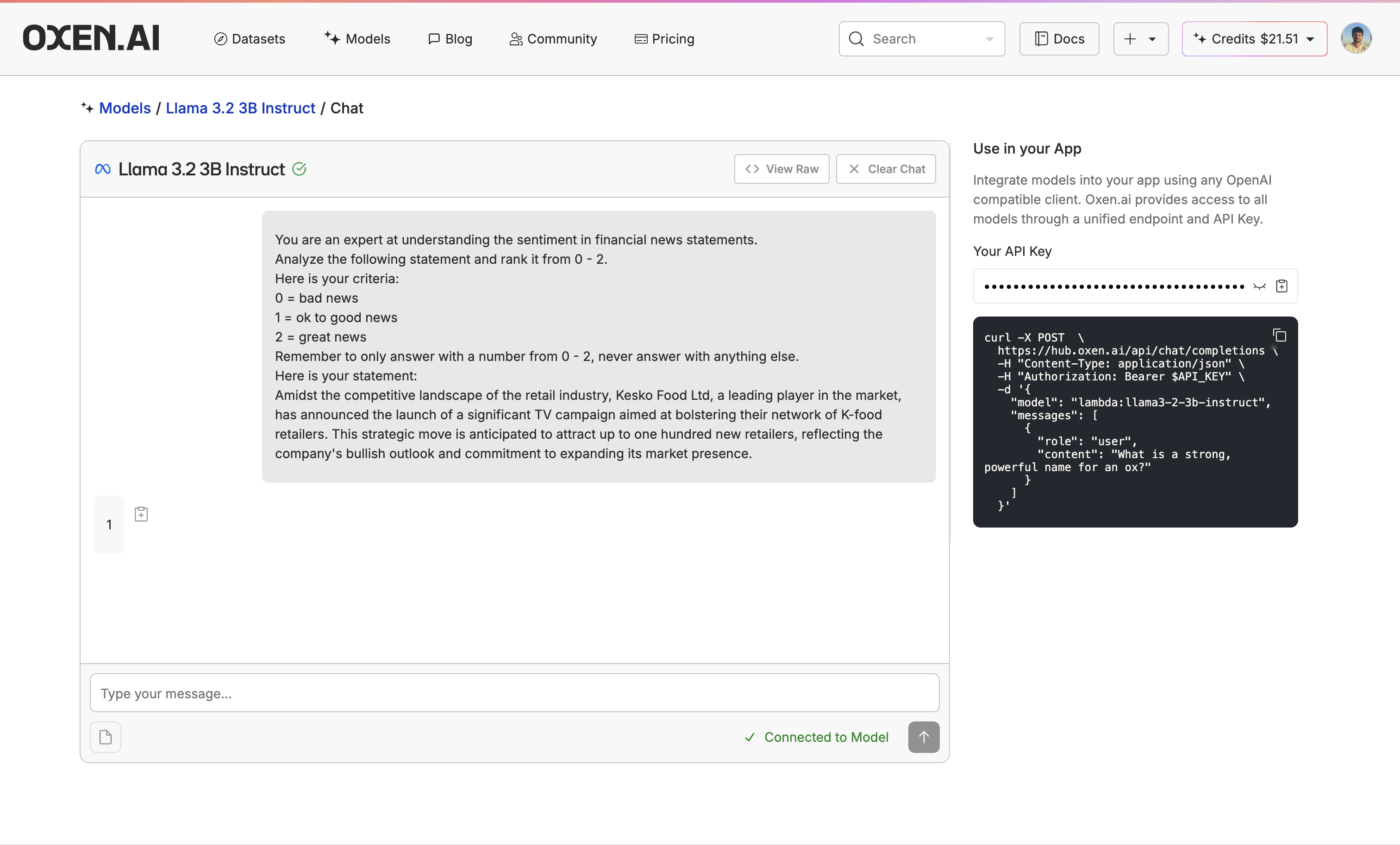
3. Evaluate the Base Model
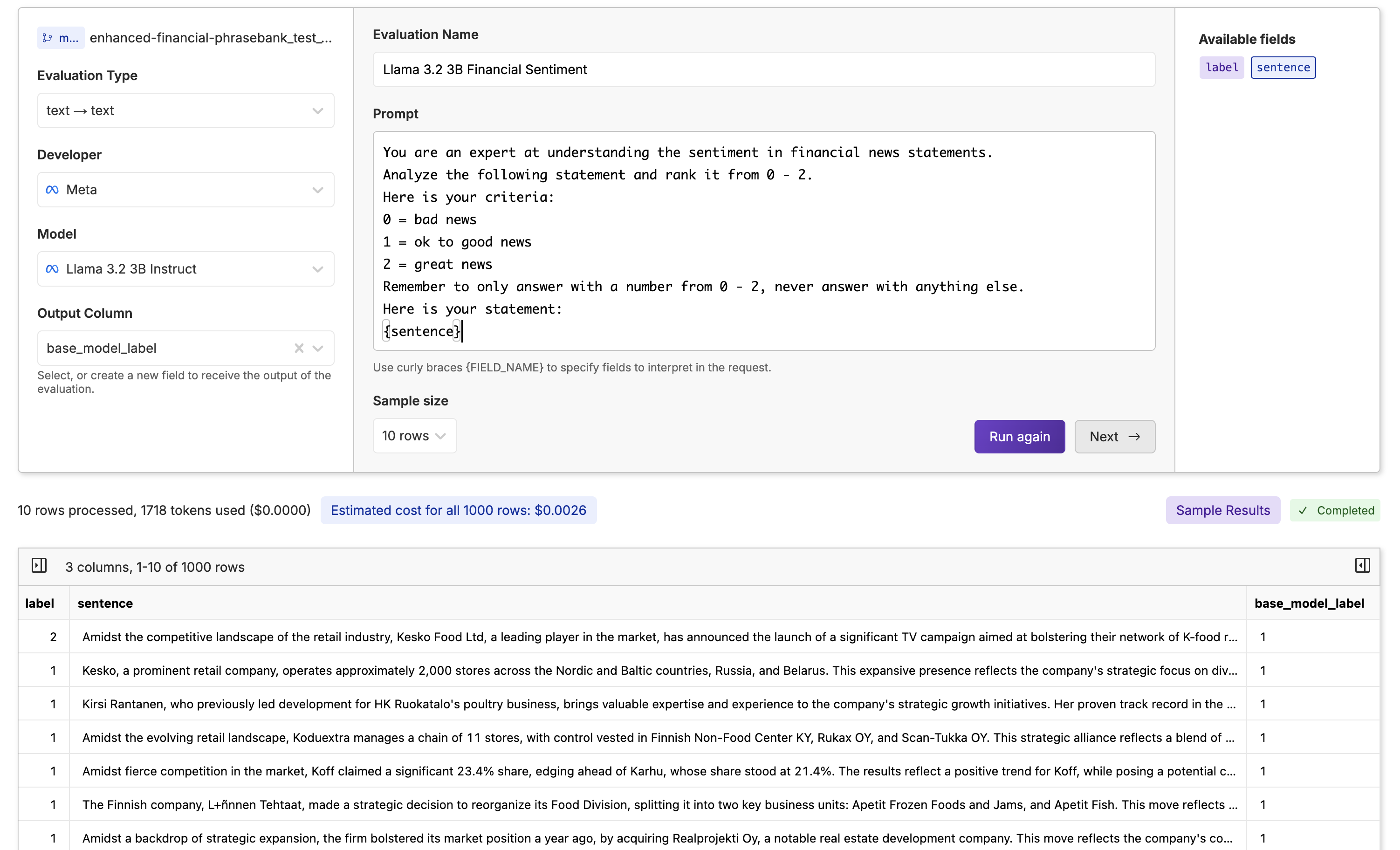
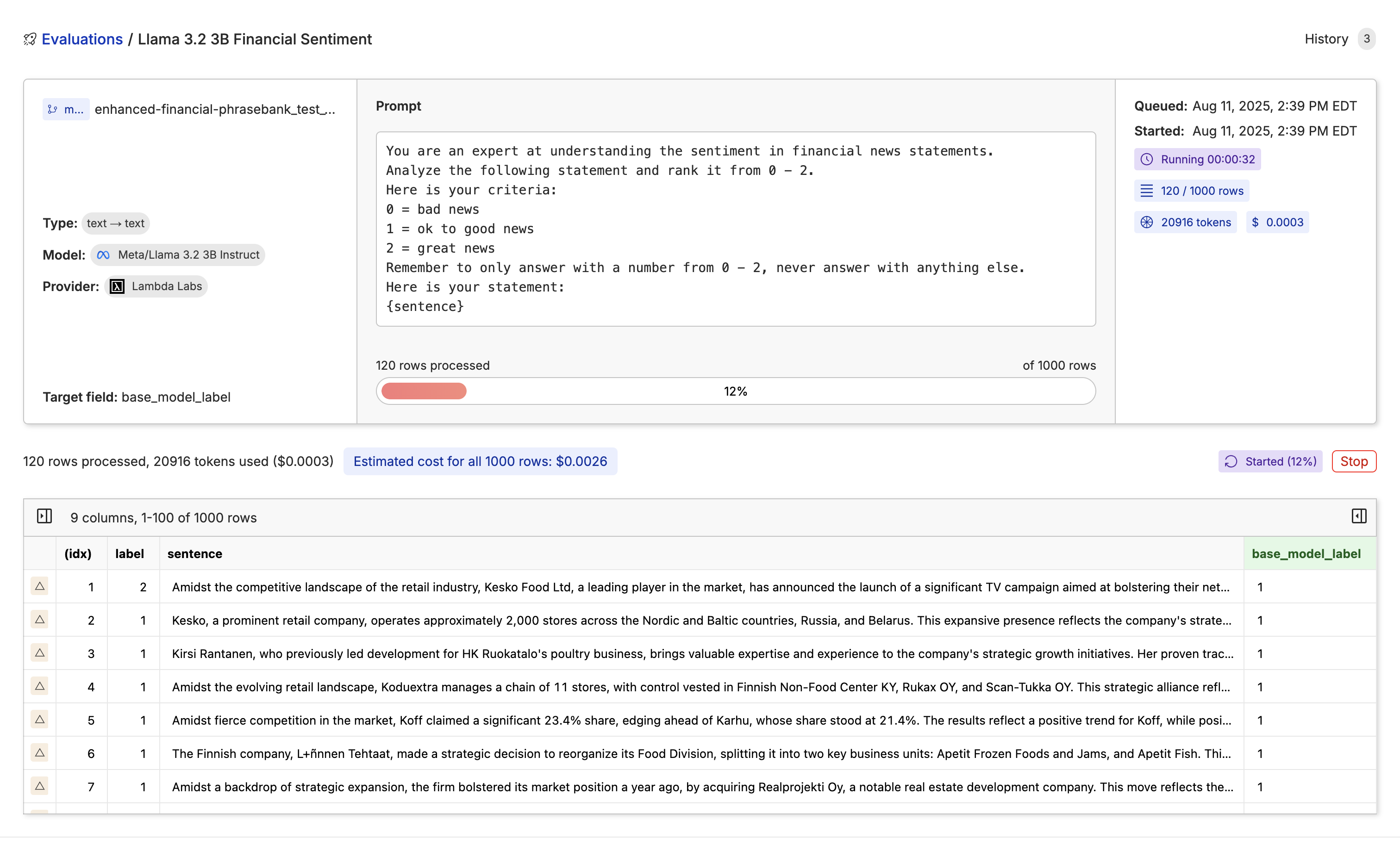
Before fine-tuning, let’s evaluate Llama 3.2 3B to see if fine-tuning improves it. We can do this with our Model Inference tool. First, go to your test dataset (not your training dataset, as you would be evaluating your fine-tuned model on the test dataset), click “Actions” and select “Run Inference”.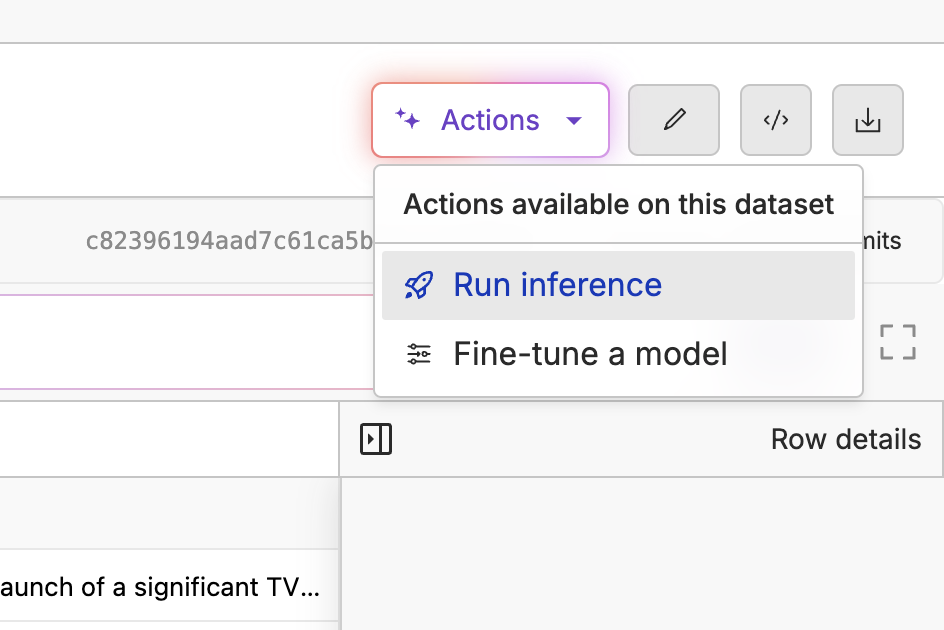
4. Fine-Tuning Llama 3.2 3B
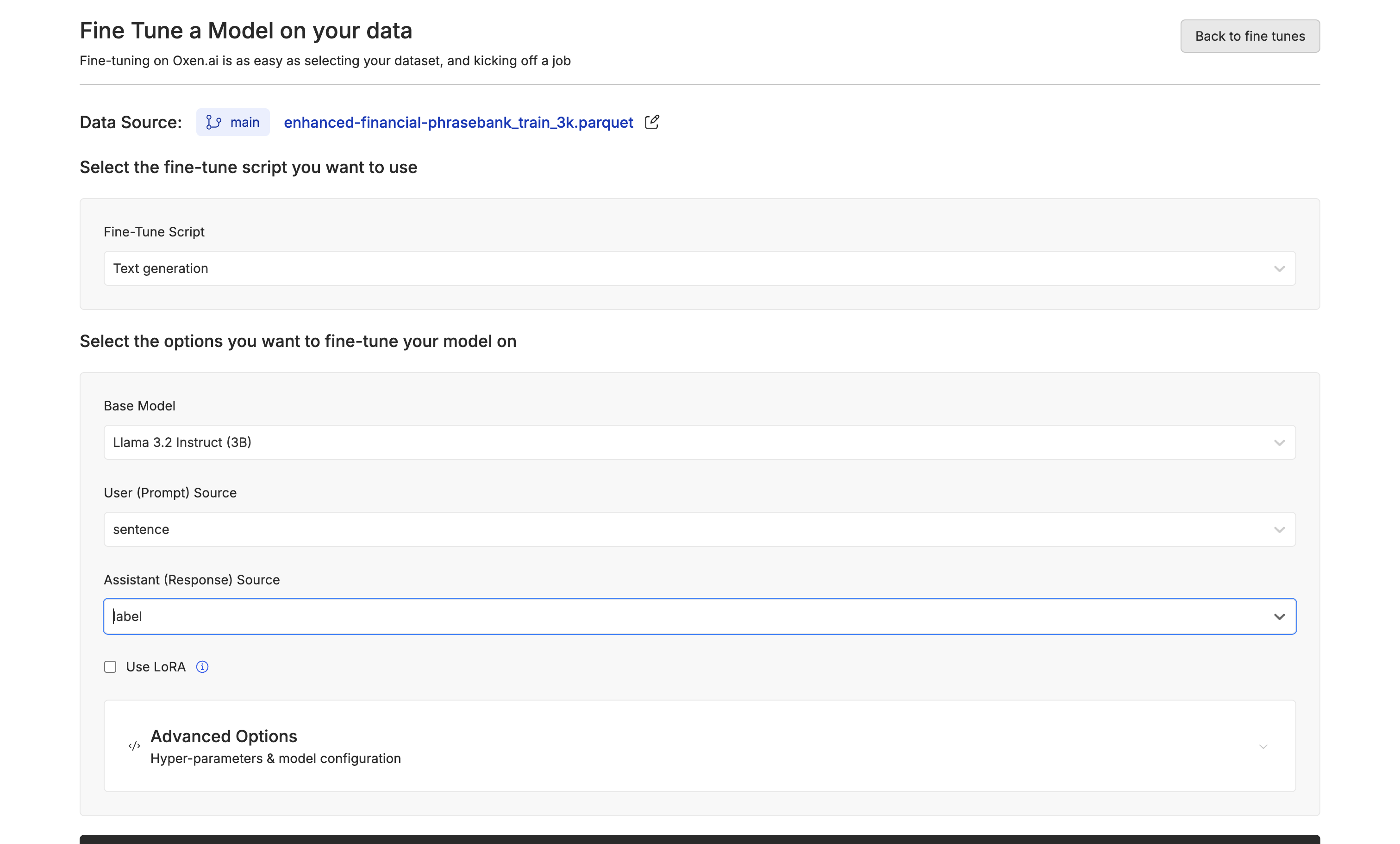
Next, let’s fine-tune Llama 3.2 3B on our dataset. Go to the train dataset, click “Actions” and select “Fine-tune a model”.
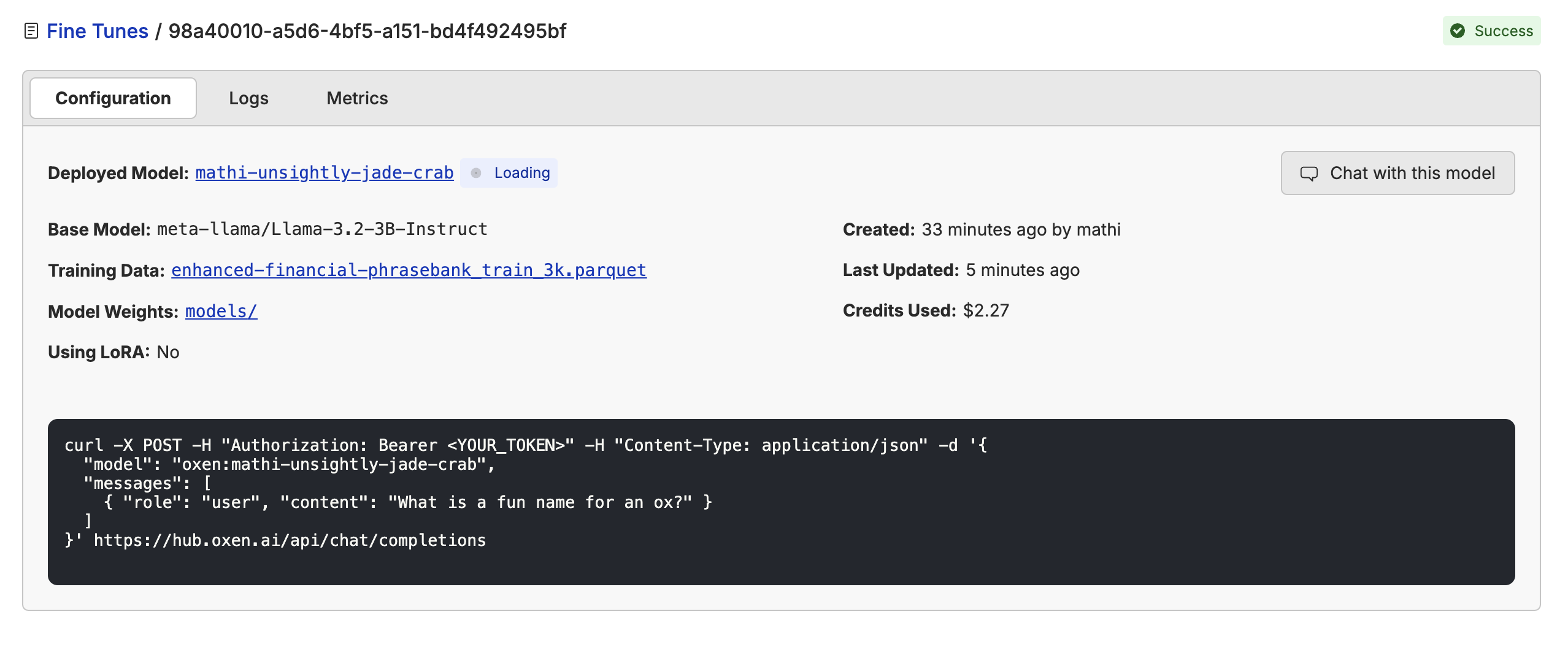
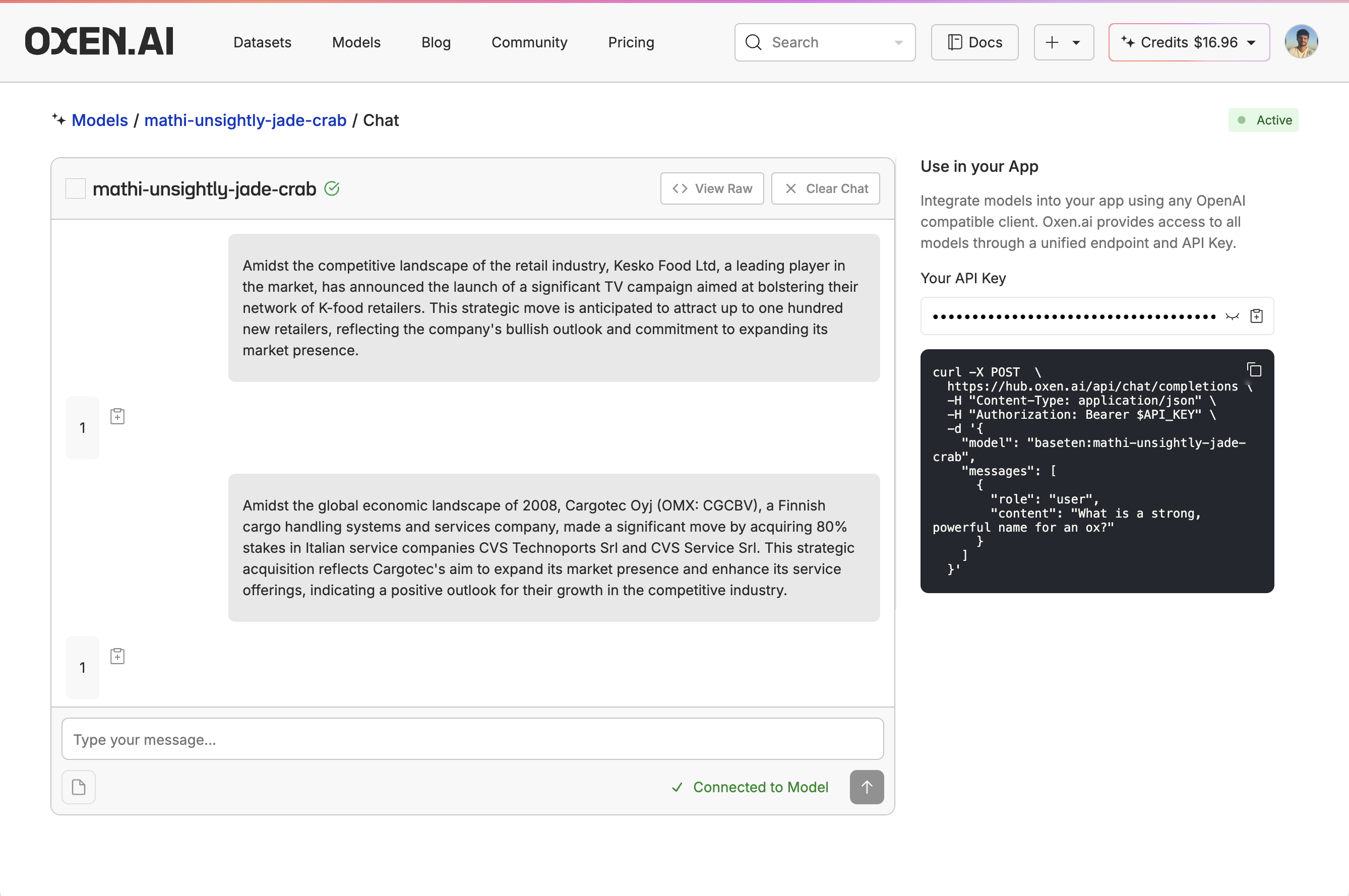
5. Evaluate the Fine-Tuned Model
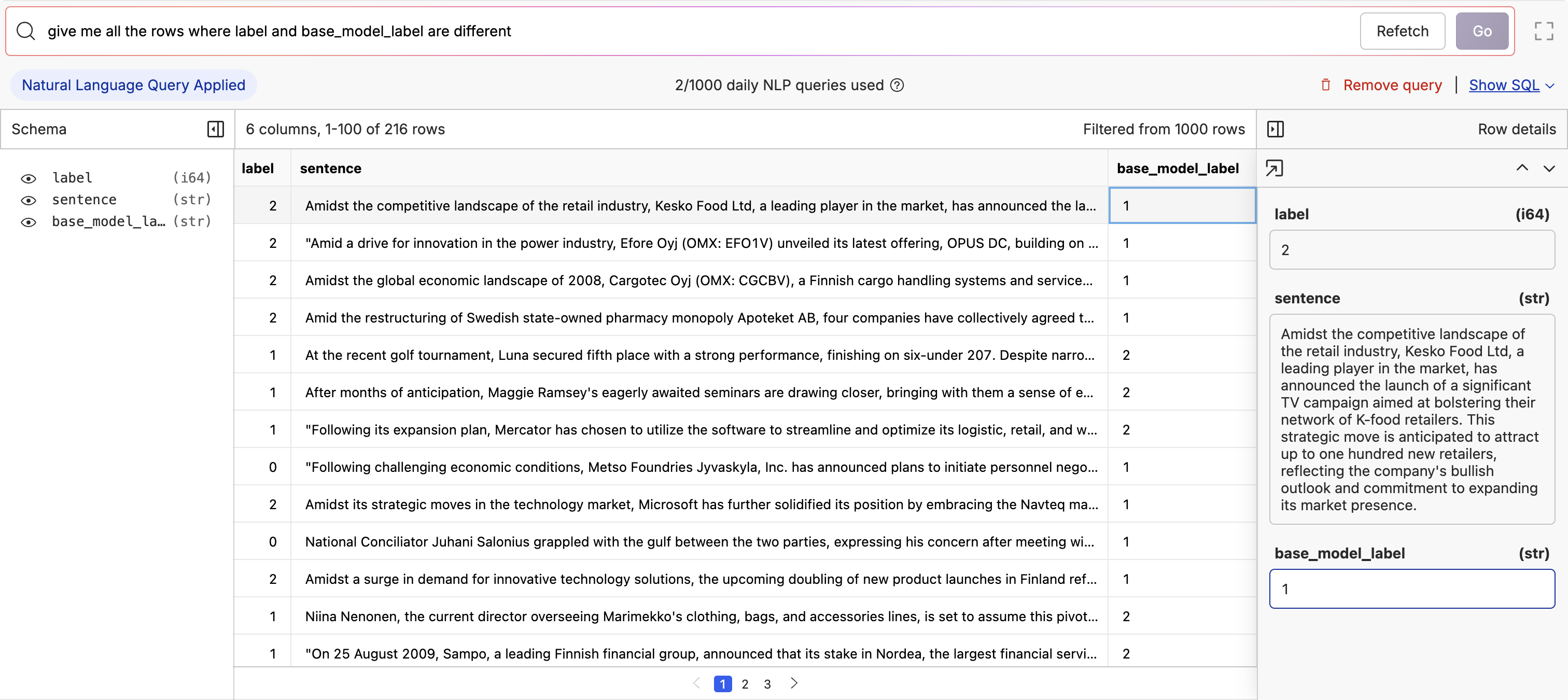
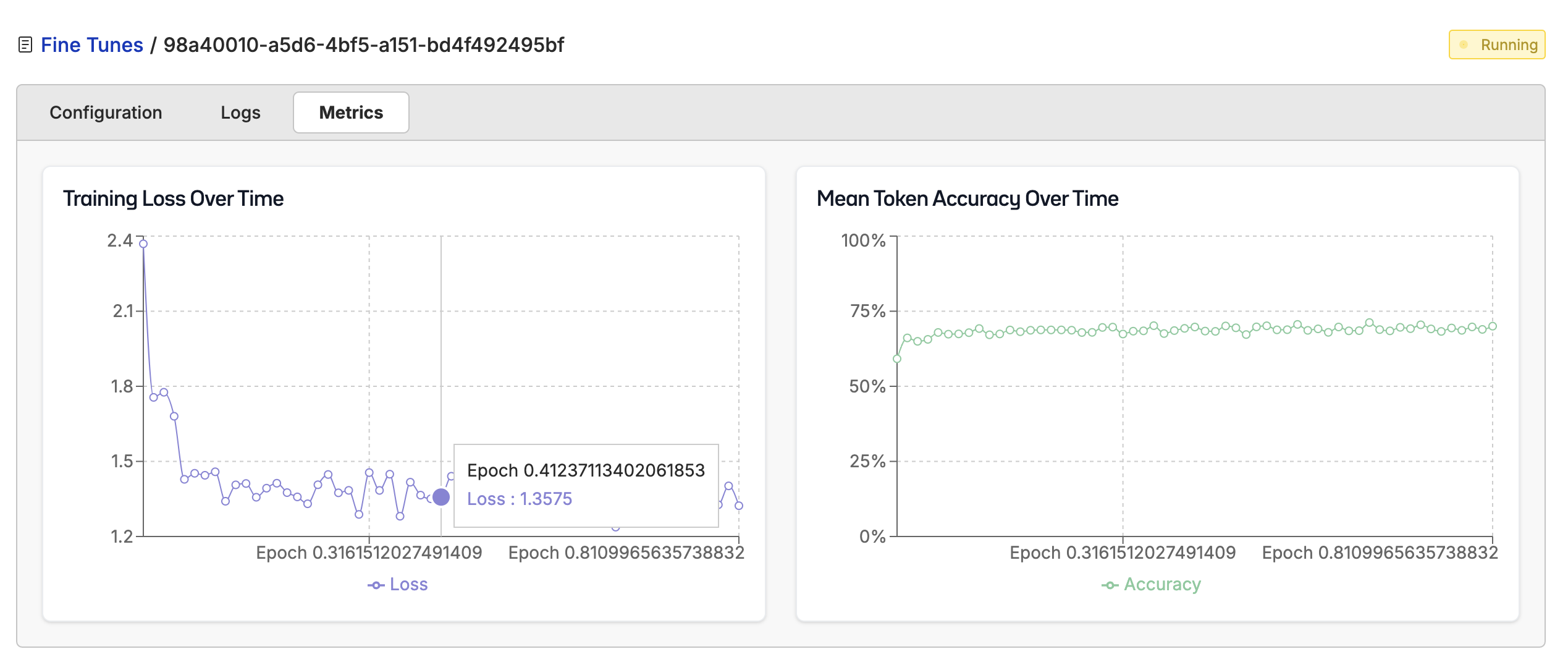
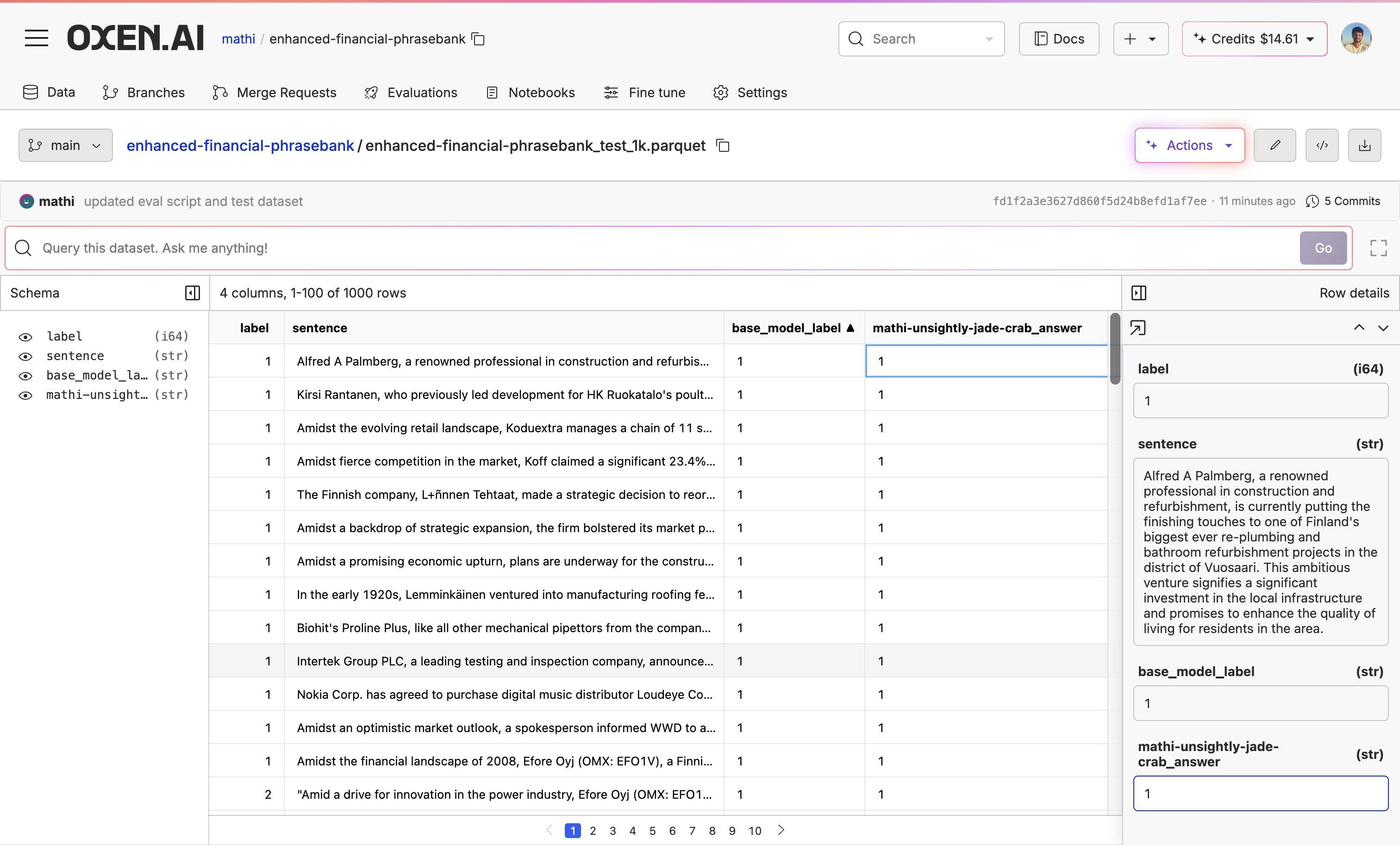
Now the fine-tuning is complete, let’s evaluate the new model and compare it with our base model. I wrote a script that used the model API to run the model over the test dataset and then created a new column named after the model (in this casemathi-unsightly-jade-crab_answers) with the model’s responses.
The advantage of our unified API is that I was able to reuse an old evaluation script and just change the model name and the dataset it was evaluating instead of writing a new API configuration.
While it seems like the model is doing pretty well, we can see there are still a couple of mistakes.
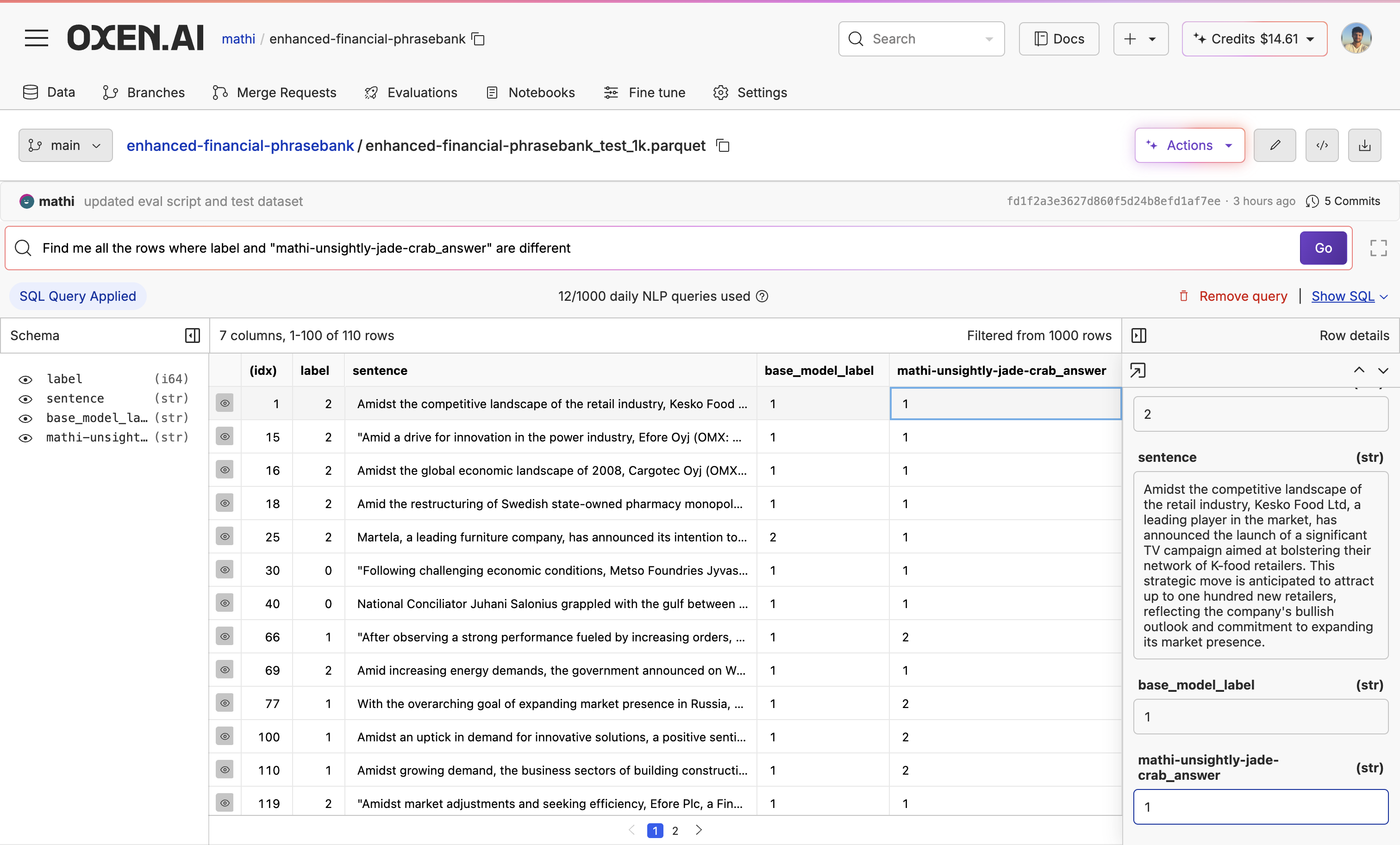
6. Next Steps
If you are happy with the results, start using the model API. If not, there are many ways we can try to improve the model:- Plow through the data and see if you need to clean, augment, or transform it.
- Keep fine-tuning different models to see which works best for your use case and data.
- Tweak the advanced settings to see if you can get a better model.
In addition to simplifying your fine-tuning pipeline, Oxen.ai offers fine-tuning consultations and services if you are struggling with training a production-ready model. Sign up here to set up a meeting with our ML experts.