Documentation Index
Fetch the complete documentation index at: https://docs.oxen.ai/llms.txt
Use this file to discover all available pages before exploring further.
One of the most reliable ways to evaluate an LLM is to have a human in the loop reviewing each input and output pair. Having human eyes not only will catch errors that the LLM missed, but it will also spark ideas for how to improve the model. Once you have a dataset of labeled examples, you can use it to train a new model, or compare the performance of different models.
This tutorial will show you how to build a simple labeling tool that allows a human to review the output of an LLM, and give a thumbs up or down (👍/👎). All your labeled data will be versioned and stored in an Oxen.ai repository so that you can always go back and see how the model’s performance evolved over time and iterate on it with your team.
Example: Asking questions about Oxen.ai’s Python Library
For this example, we will see how well an LLM can answer questions about developer docs. We will use the Oxen.ai Developer Docs as our context. This tutorial will show you how you can prompt an LLM with context, save the outputs, and build an interface to have a human review the output.
Follow along with the example notebook by running it in your own Oxen.ai account.
Creating the Dataset
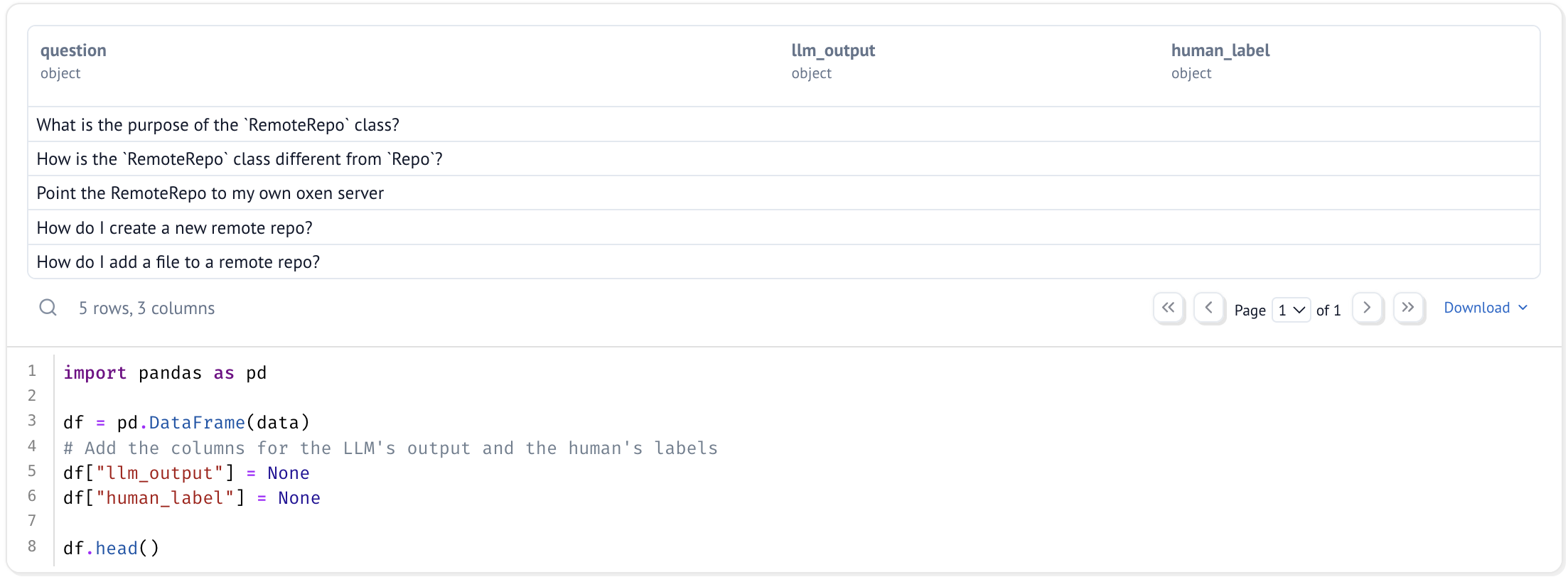
The dataset will consist of 10 questions about the RemoteRepo Python class. For your use case, a small dataset is better than none, and you can always scale up. Even if it is only a few examples to start, this allows you to setup and kick off your data flywheel.
data = [
{"question": "What is the purpose of the `RemoteRepo` class?"},
{"question": "How is the `RemoteRepo` class different from `Repo`?"},
{"question": "Point the RemoteRepo to my own oxen server"},
{"question": "How do I create a new remote repo?"},
{"question": "How do I add a file to a remote repo?"},
{"question": "How do I remove a file from a remote repo?"},
{"question": "How do I update a file in a remote repo?"},
{"question": "How do I clone a remote repo?"},
{"question": "How do I push a file to a remote repo?"},
{"question": "How do I list the files in a remote repo?"},
{"question": "How do I get the contents of a file in a remote repo?"},
{"question": "How do I delete a file in a remote repo?"},
]
import pandas as pd
df = pd.DataFrame(data)
# Add the columns for the LLM's output and the human's labels / reasoning
df["llm_output"] = None
df["human_label"] = None
df.head()
Using a Model
For this example, we will be using gpt-4.1-nano to see if OpenAI’s fast and cheap model can perform the operations we need.
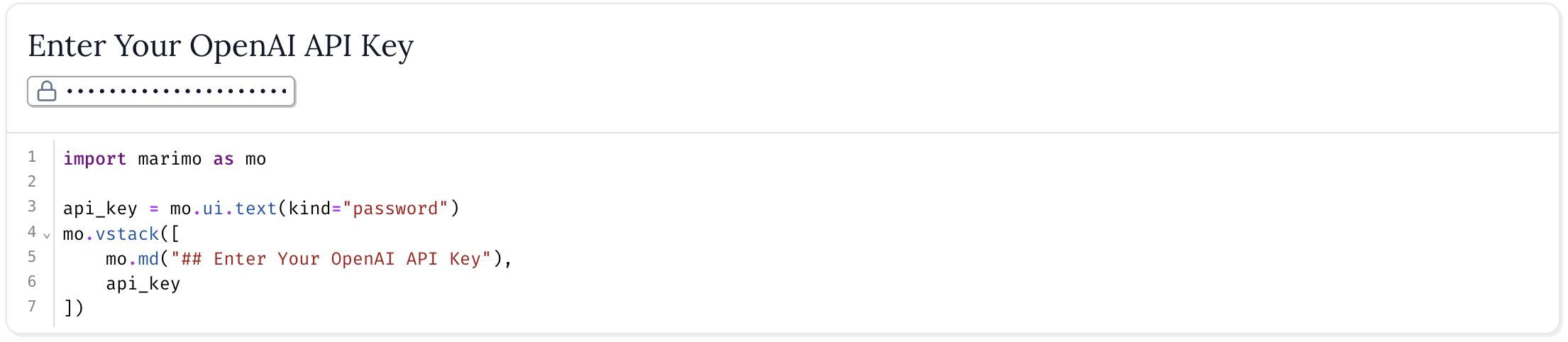
To start, make a cell at the top of the notebook that allows the user to put in their own OpenAI API_KEY.
import marimo as mo
api_key = mo.ui.text(kind="password")
mo.vstack([
mo.md("## Enter Your OpenAI API Key"),
api_key
])
 We can then use the output of this cell to stop execution further down in the notebook until the user has put in their API_KEY.
We can then use the output of this cell to stop execution further down in the notebook until the user has put in their API_KEY.
mo.stop(not api_key.value)
Building the Context
For updates to developer docs, it is best to assume the model does not yet know the latest information. To help the model, we can provide it with the latest docs as context.
import requests
def fetch_github_raw_text(url):
response = requests.get(url)
response.raise_for_status()
return response.text
url = "https://raw.githubusercontent.com/Oxen-AI/docs/refs/heads/main/python-api/remote_repo.mdx"
docs_context = fetch_github_raw_text(url)
docs_context
def llm(question: str, context: str, model="gpt-4.1-nano") -> str:
response = openai.chat.completions.create(
model=model,
messages=[
{"role": "system", "content": "You are a developer docs expert. Read the docs and answer the following question. Keep the answers short and sweet."},
{"role": "user", "content": f"Context:\n{context}\n\nQuestion:\n{question}"}
]
)
return response.choices[0].message.content
Running the Model
Now that we have our model, and our context, we can use it to answer all the questions.
mo.stop(not api_key.value)
model_name = "gpt-4.1-nano"
with mo.status.progress_bar(total=len(df)) as bar:
for idx, row in df.iterrows():
# Set the 'llm_column' column to the output from the model
df.at[idx, 'llm_output'] = llm(row['question'], docs_context, model=model_name)
bar.update()
df.head()
with mo.status.progress_bar(total=len(df)) as bar: is a Marimo feature that allows you to display a progress bar in the notebook to help you visualize the progress of the loop. This is helpful when you have more than 10 examples and want to know how much longer the loop will take.
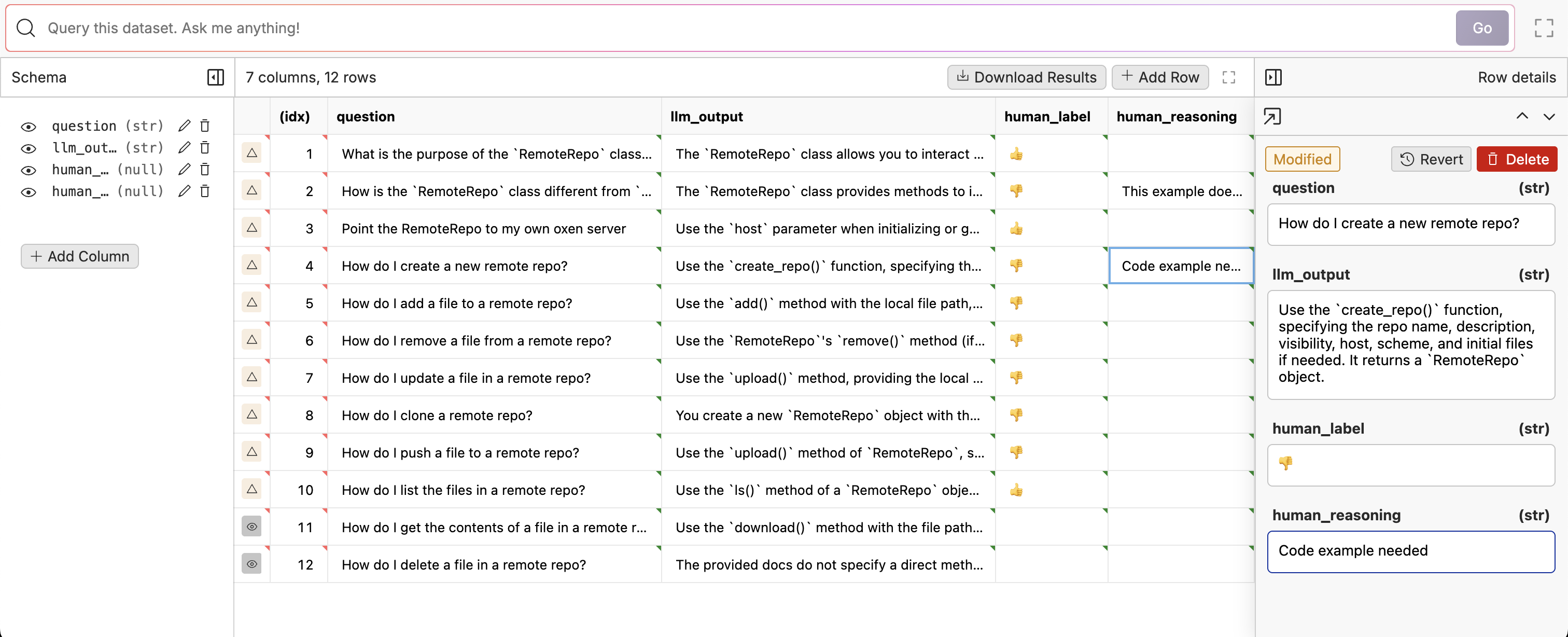
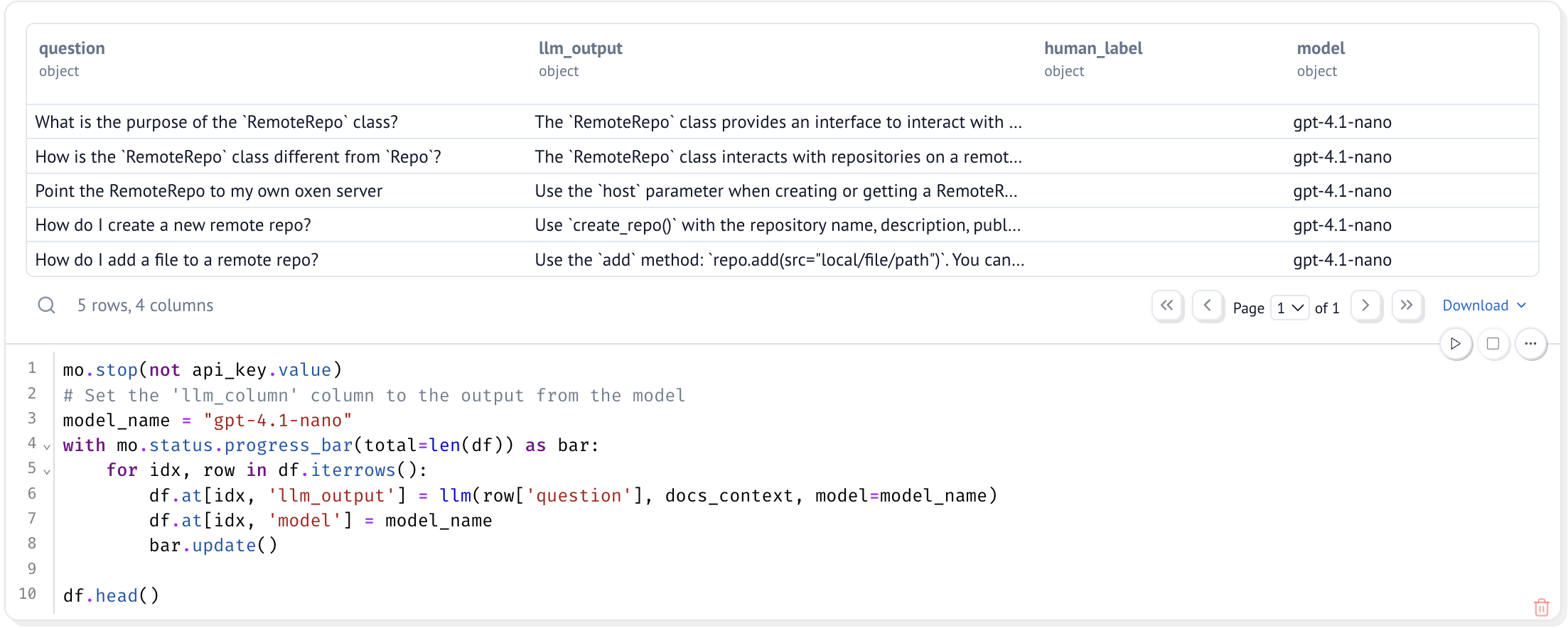
 After we have run the model, the dataset should look like this:
After we have run the model, the dataset should look like this:
 PS: If you want to play with different prompts and models without having to write code, you can use also use the Oxen.ai Model Inference Playground for this part.
PS: If you want to play with different prompts and models without having to write code, you can use also use the Oxen.ai Model Inference Playground for this part.
Saving the Results
Before we build our labeling tool, let’s save the results to Oxen.ai.
from oxen import RemoteRepo, DataFrame
# Save to oxen in a file called `results/gpt-4.1-nano.jsonl`
repo = RemoteRepo("ox/Oxen-Docs-RAG", host="dev.hub.oxen.ai")
file_name = f"{model_name}.jsonl"
df.to_json(file_name, orient="records", lines=True, index=False)
output_dir = "results"
path = f"{output_dir}/{file_name}"
if not repo.file_exists(path) or repo.file_has_changes(local_path=file_name, remote_path=path):
repo.add(file_name, dst=output_dir)
repo.commit(f"Got results for labeling from {model_name}")
else:
print("No changes!")
# Instantiate a DataFrame object to use in our labeling tool
remote_df = DataFrame(repo, path)
remote_df that we can use in our labeling tool.
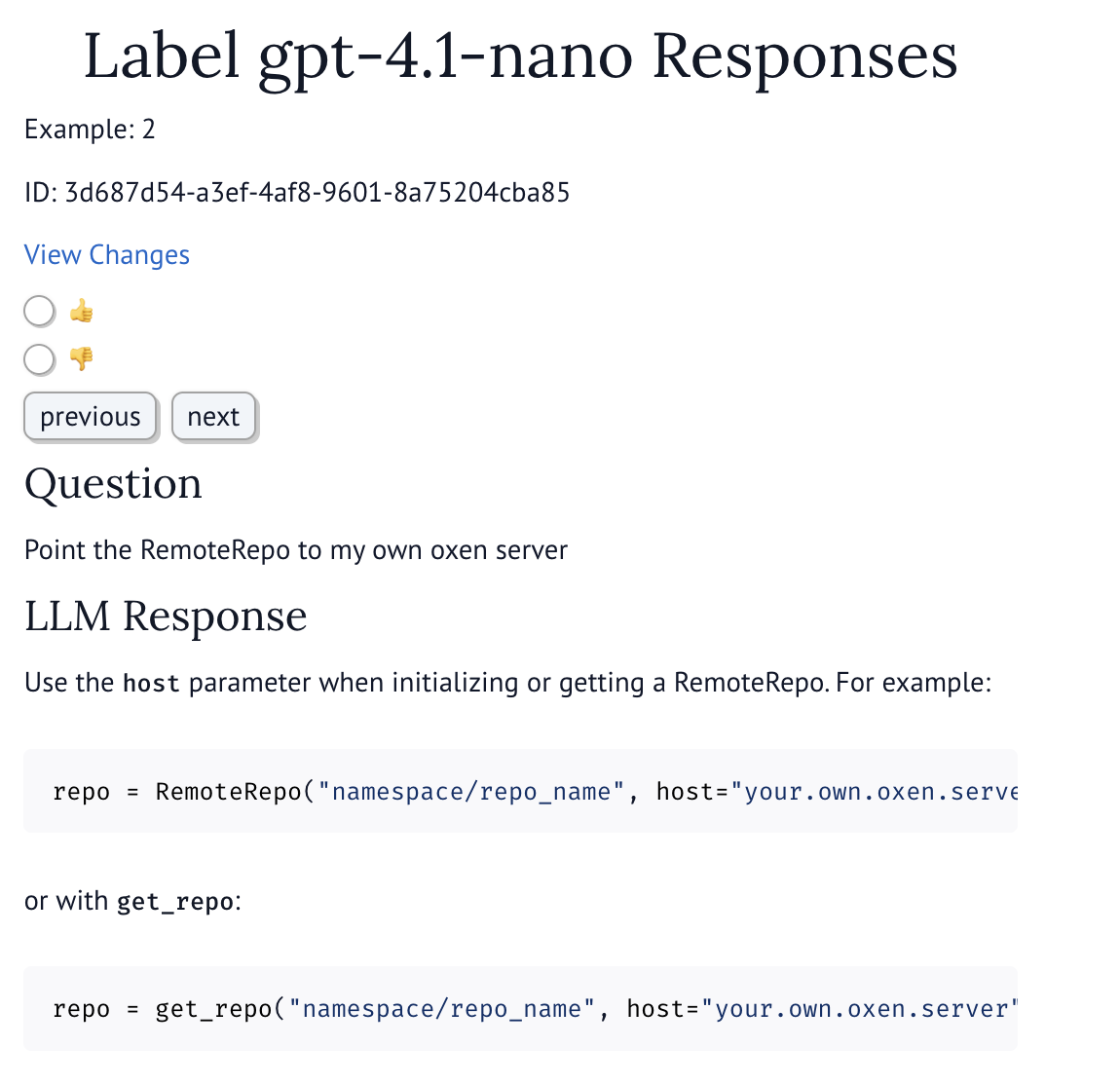
Now that we have the results saved, we can build a simple labeling tool to label the results. We’ll need some state to keep track of the current index of the dataframe, and the current row.
get_index, set_index = mo.state(0)
def update_label(remote_df, id, value):
remote_df.update_row(id, {"human_label": value})
increment_index()
def increment_index():
set_index(lambda v: v+1)
def decrement_index() -> int:
set_index(lambda v: max(0, v - 1))
def get_row(remote_df, idx):
data = remote_df.get_row(idx)
return data[0]
# Get the current index from the state variable
row_idx = get_index()
# Get the row at the current index
current_row = get_row(remote_df, row_idx)
# Create a radio button for the user to select the label
label_picker = mo.ui.radio(
["👍", "👎"],
value=current_row["human_label"],
on_change=lambda v: update_label(remote_df, current_row['_oxen_id'], v),
)
# Create a button to move to the next row
next_button = mo.ui.button(label="next", on_change=lambda _: increment_index())
# Create a button to move to the previous row
previous_button = mo.ui.button(label="previous", on_change=lambda _: decrement_index())
# Display the UI
mo.vstack([
mo.md(f"# Label {model_name} Responses"),
mo.md(f"Example: {row_idx}"),
mo.md(f"ID: {current_row['_oxen_id']}"),
mo.md(f"[View Changes]({remote_df.workspace_url()})"),
label_picker,
mo.hstack([previous_button, next_button], justify="center"),
mo.md("## Question"),
mo.md(current_row['question']),
mo.md("## LLM Response"),
mo.md(current_row['llm_output']),
])
remote_df.commit() method.
remote_df.commit(f"Labeled responses for {model_name}")